


Even though Kubernetes was originally developed to simplify container management and configuration, it’s known to be a complex ecosystem of multiple services. Before you leverage Kubernetes for container orchestration and deploy workloads into production, you need to understand the intricacies of its ecosystem.
In this article, we’ll discuss eight things to know before using Kubernetes in production, eight Kubernetes cluster components, eight key considerations, and eight best practices for managing a Kubernetes cluster.
8 things to know before using Kubernetes in production
Kubernetes leverages an API-based architecture that makes it portable and flexible, so it can be used in different environments and in conjunction with most modern technologies. Kubernetes allows users and services to interface with the cluster through API objects. The eight foundational API objects that represent a cluster state are:
- Pod - An object that encapsulates one or more containers and is the smallest execution unit in a Kubernetes ecosystem.
- ReplicaSet - A controller that runs multiple instances of a pod to ensure that the number of pods always meets workload requirements.
- Services - Groups a logical set of pods and embeds an access policy that enables routing, service discovery, and load balancing between the pods.
- Volume - Represents a data directory for retaining data that’s available to containers within a pod.
- Namespace - A virtual abstraction that separates the cluster into isolated units.
- ConfigMaps & Secrets - Used to inject data into containers by separating their definitions from pod specs.
- StatefulSet - A Kubernetes API object used to deploy and scale pods for stateful applications.
- DaemonSet - Used for scheduling and for ensuring that at least one pod runs on every available node of the cluster.
8 Kubernetes cluster components
Kubernetes orchestrates containerized workloads and services in groups of machines (nodes) called clusters — which are further supported by a number of components for container orchestration and workload management.
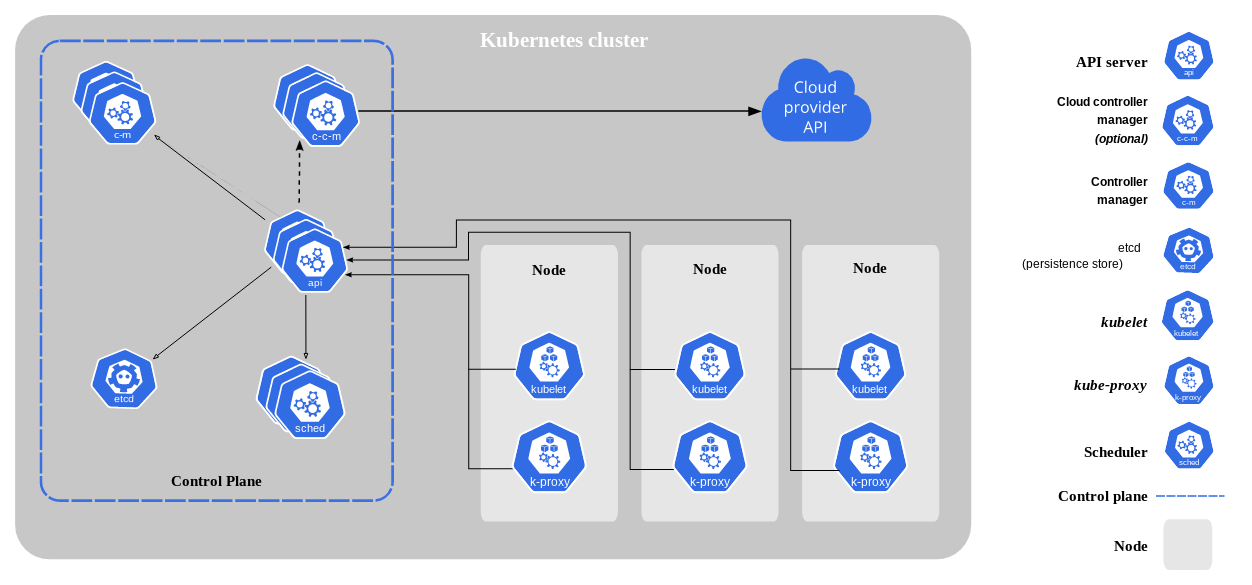
Each Kubernetes cluster is composed of:
- Nodes - Represent a physical or virtual machine with the container runtime to support one or more containers. Nodes in an operating cluster can be categorized into:
- Master node- Hosts the cluster’s control plane and is responsible for scheduling workloads, scaling, and managing the cluster state. Each cluster must have at least one master node; however, a typical choice is to provision two or more master nodes for redundancy.
- Worker node - Hosts workloads in containers and performs the duties assigned to it by the master node. - Control plane - Composed of a number of cluster components, it’s responsible for controlling the cluster to achieve a desired state.
- Kube-API server - The front-end server that manages all external communication with the cluster.
- Etcd - The key value database that stores cluster state and data.
- Kube-scheduler - Uses etcd event data to schedule workloads on worker nodes.
- Kube-controller manager - Runs a set of controllers that govern the state of the cluster
- Kubelet - An agent that runs on each worker node to communicate with the API server, it’s responsible for the deployment of containerized workloads in pods.
- Kube-proxy - Maintains network rules that allow communication between pods and services, both internal and external to the cluster.
8 key considerations for a production-grade Kubernetes cluster
Things to consider when building production-grade clusters include:
Cluster monitoring and logging
A complex Kubernetes cluster typically contains several containerized applications deployed on hundreds of nodes — with each node hosting multiple pods. Comprehensive logging and monitoring are critically important, because they help identify defects on time, subsequently preventing business disruptions and poor user experience. Monitoring exposes infrastructure metrics that can be used to improve resource utilization and efficiency, while logging captures all cluster events for analysis and troubleshooting.
Infrastructure as code
Kubernetes relies on declarative configurations (through an Infrastructure as code [IaC] model) for rapid cloud-native deployments. By enabling test automation in staging environments, an IaC methodology helps deploy repeatable and consistent infrastructure at scale. Elimination of manual configuration, lower costs, and fewer errors are some additional benefits of adopting an IaC model.
GitOps for deployment velocity and disaster recovery
As opposed to smaller deployments, production environments should rely on a single source of truth for infrastructure configuration and management. Adopting a GitOps model enables real-time declarative infrastructure management for seamless rollout of changes, while allowing for rapid rollbacks in the event of faulty updates.
Security and compliance
As production workloads contain sensitive data, security and compliance are key elements of managing a Kubernetes ecosystem. Instead of formulating security controls from scratch, cluster administrators can employ security benchmarks to avoid misconfigurations and mitigate active threats. Maintaining a robust security posture, a primary objectives of most regulatory bodies, that encompass various data-retention and governance policies for comprehensive security is critical.
Secrets management
Secrets in production should not be hardcoded to prevent misuse. Using a third-party secret management system, such as the HashiCorp Vault, is often recommended for secure management and administration of secrets. Encrypting secrets before storing them, enforcing a circle of trust, secret rotation, applying the principle of least privilege, and regulatory compliance are other core aspects of an efficient secrets management system.
Self-hosted vs. managed Kubernetes
The choice between self-hosted and managed Kubernetes services depends on workload type, regulatory obligations, and budget. Self-managed Kubernetes is considered appropriate for organizations that have the expertise needed to build and operate distributed clusters. Although such setups are ideal for organizations with security and compliance concerns, self-hosted instances add to the overhead of managing cluster intricacies and are expensive to maintain. Managed Kubernetes services (such as AKS, GKE, and EKS), on the other hand, aid in cluster maintenance and configuration through dedicated hosting, migration assistance, pre-configured deployments, and enterprise support.
Centralized Ingress
Kubernetes Ingress is an API object that defines the flow of external traffic into cluster services. Leveraging a centralized ingress controller simplifies load balancing, encrypts all incoming traffic, and forwards traffic to appropriate pods, subsequently helping automate HTTPS and SSL administration while offering centralized control over exposing services securely.
Portability and scalability
Building minimal container images supports portability by standardizing the software delivery lifecycle. Workloads can be packaged as microservices, which can easily be moved across deployment environments, scaled for sudden usage spikes, and decommissioned without impacting other services.
8 best practices for managing a Kubernetes cluster in production
Deploying Kubernetes applications for production requires a thorough assessment of workload and environment configurations. While organizations may adopt different optimization options based on use cases, some recommended practices for managing a Kubernetes cluster in production are:
Use the latest Kubernetes version
As Kubernetes frequently introduces new features and security patches, it’s important to use an updated, stable version of Kubernetes in a production-grade cluster. In addition to fixing known vulnerabilities, an updated version enhances core features of the platform, including support for additional network plugins, inclusion of new API extensions that allow more control over cluster lifecycle management, and dynamic provisioning of cluster resources.
Enforce resource isolation using namespaces
Namespaces help optimize the cluster by grouping, organizing, and isolating cluster resources and objects. Cluster administrators should leverage namespaces to share the same cluster resources between separate teams working in different environments (dev, QA, and production). Namespace-defined access controls also help administer robust security and enhance performance through resource isolation and efficient capacity management by defining resource quotas per namespace.
Implement role-based access control
Role-based access control (RBAC) enforces fine-grained permission management by ensuring that users have access only to resources needed for specific functions. With RBAC, administrators can adopt the least privilege principle to restrict attacks typically orchestrated by escalating privileges beyond a designated scope.
Enforce version control for resource manifests
All configuration manifests for Kubernetes objects and resources should be stored in version control to help keep track of modifications to code. With version control, changes made to manifest files are seamlessly replicated across defined environments, while previous versions are retained for simple rollbacks. Version control also enables cross-functional collaboration while retaining a history of changes and avoiding module-level conflicts.
Use labels and selectors to simplify resource management
Labels are key-value annotations that allow DevOps teams to attach metadata and other meaningful information that identify attributes of Kubernetes objects, including deployments, services, and pods. Similar to labels, label selectors are grouping attributes for grouping and identifying a set of Kubernetes objects. Using metadata through labels and selectors simplifies the segregation of cluster objects, to aid in searching, categorizing, and operating deployments at scale.
Set resource requests and limits for pods
For optimum utilization of cluster resources (CPU and memory) and enhanced scheduling efficiency, Kubernetes offers requests and limits as critical mechanisms that help define the cluster resources that a pod or container can consume. To schedule workloads evenly across nodes, it’s recommended that you appropriately configure:
- Resource requests - Represent the minimum resources required by a pod to be scheduled on an appropriate node.
- Resource limits - Represent the maximum amount of resources a pod can use, to prevent resource wastage
Use minimal images
Base images typically contain unnecessary packages and libraries that consume container resources. Where possible, using smaller container images like Alpine images is recommended; such images require fewer resources and enable rapid container builds and scheduling. Although base images can always be reconfigured to include additional packages and libraries, maintaining a minimal image reduces the attack surface while minimizing the overhead of maintaining compliance and resolving configuration conflicts.
Perform regular log audits
Turn on audit logging when initiating the Kube-API server to observe all requests made to the cluster. Regular inspection of these requests helps identify the root causes of cluster events that result in security and performance issues. Deploying log aggregation tools such as the ELK stack or Fluentd also help perform deeper analysis to optimize cluster security policies and regulatory compliance.
Final thoughts
While deploying applications on local Kubernetes clusters is a relatively straightforward task, organizing production-grade clusters requires significant analysis and planning. This is often because a production-grade deployment requires thoroughly considering performance, compliance, security, and availability. It’s equally important to assess challenges and methodically adopt best practices, in order to ensure that deployments are consistent, predictable, and efficient.
If you're looking to build an internal UI to manage and organize your clusters efficiently, then Airplane is a good fit for you. Airplane is the developer platform for building internal tools. With Airplane, you can transform scripts, queries, APIs, and more into powerful internal workflows and UIs easily. Airplane also offers strong built-ins, such as approval flows, job scheduling, permissions setting, and more.
Sign up for a free account or book a demo to test it out and build powerful internal tools quickly.


