


As organizations shift additional workloads to containers, a container orchestration system is required in order to facilitate automation. Kubernetes, the leading open-source container orchestration system has gained massive support from small and large organizations across numerous industries.
The widespread adoption of Kubernetes has created a huge opportunity for talented engineers who understand Kubernetes and can manage complex workloads on K8s.
In this cheat sheet, we provide an in-depth guide on working with Kubernetes objects to familiarize you with how these persistent entities, which represent the state of your cluster, fit together.
What are Kubernetes objects?
Kubernetes objects are represented in JSON or YAML files and describe the state of your cluster. The state of the cluster defines what workloads should be running in it. You can create these objects, and then Kubernetes makes sure that your desired state is maintained. For example, if you create a deployment in Kubernetes, it makes sure it’s running even if the cluster restarts after a crash. That’s the beauty of Kubernetes.
There are two categories of objects in Kubernetes, which we’ll discuss more later on:
- basic objects: Pods, Service, Volumes, Namespace, etc., which are independent and don’t require other objects
- high-level objects (controllers): Deployments, Replication Controllers, ReplicaSets, StatefulSets, Jobs, etc., which are built on top of the basic objects
You can get to a desired state by creating an object and pushing it to the Kubernetes API with client-side tools like kubectl.
Now, let’s dive into a deeper exploration of how to best work with the objects that make Kubernetes function.
Object spec and status
In Kubernetes, object representation is stored in a manifest, as discussed above. Each kind of object has two specific properties:
spec: This contains the details about the object. For example, for a pod, it would contain which container image it would run, the ports to expose, the labels, and more.status: This contains your object’s current state and is updated in real time by the Kubernetes control plane. If you delete your pod, thestatuschanges toTerminating, and then the pod is no longer listed as it gets deleted. The status is automatically assigned to each object.
Required fields
Each YAML configuration for an object contains a selected set of fields for it to be valid. These fields are called required fields, and they include the following:
apiversion: This contains the instruction as to which version of the Kubernetes API should be used to create your object from the manifest.kind: As noted above, there are two categories of objects—basic and high-level objects. This field contains the details of the type of object; for example, if you want to create a pod in your cluster, thekindwould bePod.metadata: Metadata is defined as a set of data that gives information about other data. So this property defines parameters likename,UID, ornamespacethat would help you identify your object amid other objects of the samekind. You’ll read more aboutUIDandnamespacelater in this article.spec: This, as discussed above, contains your object’s specifications. For example, it would contain what container image the pod would run, as well as what ports should be available for the object pod.

The manifest below contains all the required fields for a pod object for your reference in a YAML format:
Kubernetes object management
In the above section, you described a Kubernetes object using YAML manifests. Now, how should you deploy, edit, or delete it? Kubernetes objects can be managed either by imperative commands or declarative configuration. Using imperative commands with the kubectl command-line tool, you can create, update, and destroy Kubernetes objects directly without needing any manifest. This is very helpful when you’re deploying specific objects like a pod.
Here’s an example of some imperative commands:
However, when you need to deploy infrastructure, this method is not that helpful as you’d need to deploy many objects with many commands. In that case, you’d want to create manifests that would contain the specification of your objects, and kubectl would deploy them to your cluster at once. Here are some examples of declarative commands:
Now let’s take a look at a few operations that you can perform with your objects:
Create objects
Regardless of the type of object, Kubernetes objects can be created with the help of this basic syntax:
Here, the -f flag stands for “file name,” and apply applies the configuration stated in your object.yaml to your cluster.
Edit objects
Editing objects is as simple as using kubectl and running this command:
The above command opens the raw configuration of the object in YAML representation from the Kubernetes API and launches your $EDITOR on the file. You can edit your object configuration and then get a new desired state when you save the changes. For example, you can edit the number of replicas in a deployment without redeploying a manifest from scratch.
Furthermore, updating objects from your manifest is as simple as using the replace command with kubectl. If you have your manifest for the initial deployment, you can use the following:
Delete objects
Deleting objects is quite similar to editing them. You can use this command:
If you have the object manifest, you can also use the manifest to delete the resource using this command:
You can use either of the above two commands as per your requirements, and kubectl will talk to the Kubernetes API to delete the objects specified.
Object names and IDs
Kubernetes objects should follow a nomenclature and shouldn’t be duplicated in a
namespace. You don’t want something to be deleted when you don’t intend it to. Each object has two unique specifiers:
Name: This is the unique name for your object, and it has some restrictions. You can read
more about the specifications in this documentation.UID: UID is a unique, system-generated string standardized as SO/IEC 9834-8 and as ITU-T X.667 for the whole lifetime of the cluster. It helps you distinguish between historical occurrences of similar entities and simplifies logs. UIDs are more reliable than the name as there might be an object of the same name in the history of the cluster, but the UIDs would be distinct.
Using namespaces
Namespaces help you to divide your resources into isolation groups for ease and efficient resource management with the help of resource quotas. Creating a new namespace for your resources is simple as using the following command:
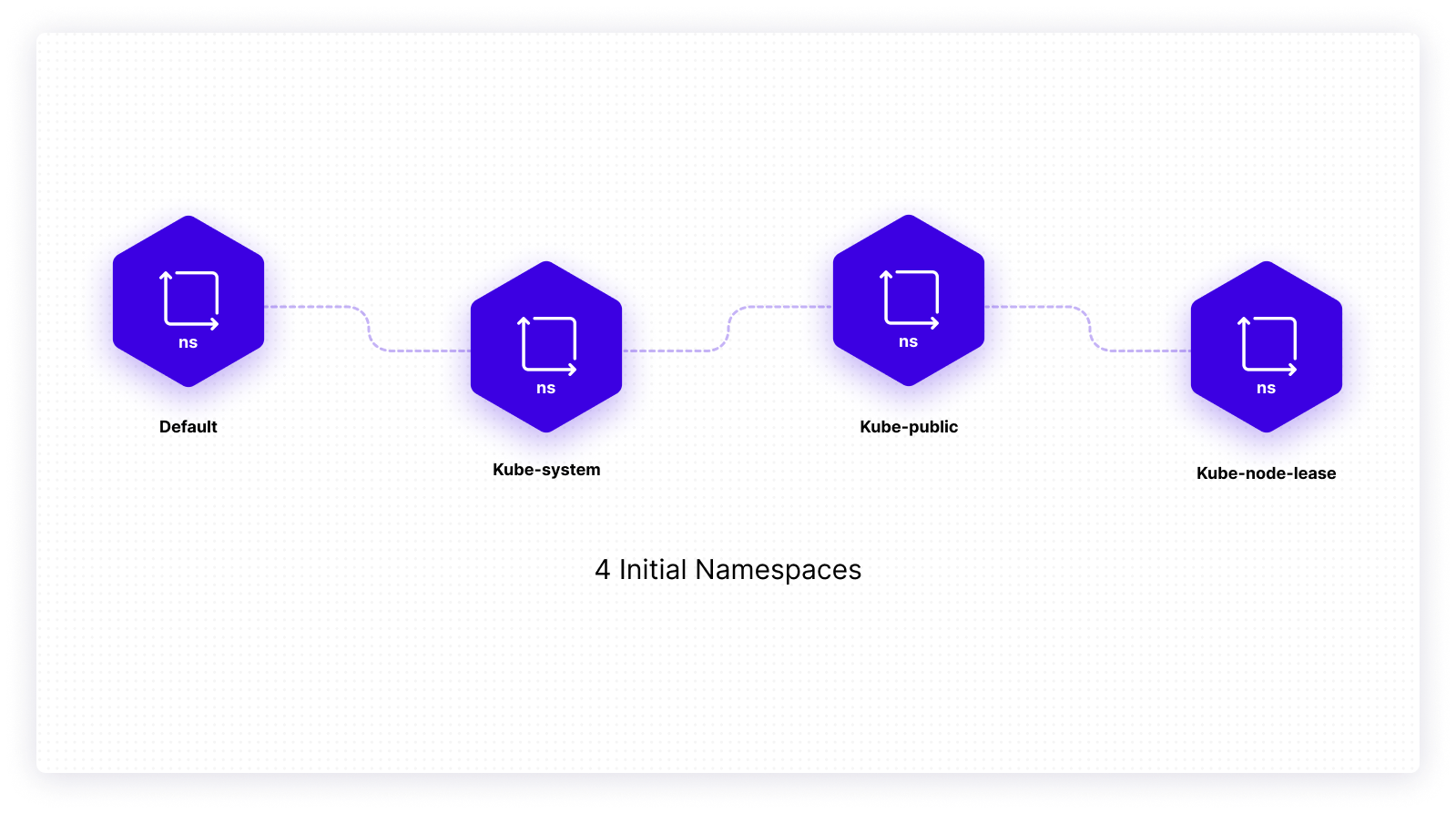
Regardless of how many namespaces you create, there will always be four initial namespaces present:
default: where your resources you create would be deployedkube-system: where the objects created by the Kubernetes system would be storedkube-public: where the resources that should be visible and publicly readable should be storedkube-node-lease: where Node Lease objects are stored.
The namespace helps isolation, but there’s a limit to what objects it can isolate. For example, you can isolate your pods but not your nodes. You can have pods, deployments, service, and other objects in a namespace, but PersistentVolumes can’t be in any namespace. To see the full list, you can run this command:
To deploy resources in a specific namespace, you can use the following:
Not only do namespaces isolate your objects, but they are also hidden from each other until you configure DNS.
Labels and selectors
Labels and selectors come in handy when you create a meaningful key-value relationship between your objects for segregation and across namespaces. Their beauty lies in the fact they allow for efficient queries and great organization.
In short, labels help you tag your pods, and selectors help you identify objects tagged with a label. Here, in metadata, we have two labels — environment and app:
You can have labels for your different environments like dev or testing, and they would help you manage the objects inside the labels together.
Annotations
Apart from labels and selectors, Kubernetes also offers annotations. Annotations are another type of metadata that can’t be used to select objects but are there for the sole purpose of providing additional context to you or your logs and act as pointers to your logging, monitoring, and analytics systems.
Annotations are mapped in a key-value format, like labels, though they don’t have nomenclature limitations. Annotations can be large, small, structured, or unstructured data as there are no restrictions.
In the above example from the Kubernetes Documentation, you can see how imageregistry is used as an annotation to tell the operator that we are pulling the image from Docker Hub and not some other repository. Annotations provide context for the human operator, and it becomes easier for the operator to find the image from a specific registry if required.
Field selectors
Kubernetes field selectors can help you select objects based on one or more resource fields. Suppose you want to select all pods that are running in the default namespace. You’d use the following command to do so:
Selecting all objects in a namespace can be achieved by using the -n flag, but what if you want to select all objects in the cluster except the namespace? Field selectors are what can help you:
You can also use more than one field selector in your command for scenarios where you need a highly specific selection. A good example would be when you need to select all pods that are running and can restart.
Finalizers
Finalizers manage and enforce certain conditions after object deletion is initiated. To understand the importance of finalizers, you should first understand the deletion process. The process of deletion can be broken into three parts:
- Kubernetes receives delete command: When you issue the
kubectl delete <object> <object-name>command, Kubernetes marks the object for deletion. Now, your object is in a read-onlyTerminatingstate. - Actions defined by finalizers: Other components take the actions defined by the finalizer, and after the steps are complete, the controller removes the associated finalizers from the target object.
metadata.finalizerscheck: Kubernetes checks themetadata.finalizersfield, and if it's empty, the object is considered deleted.
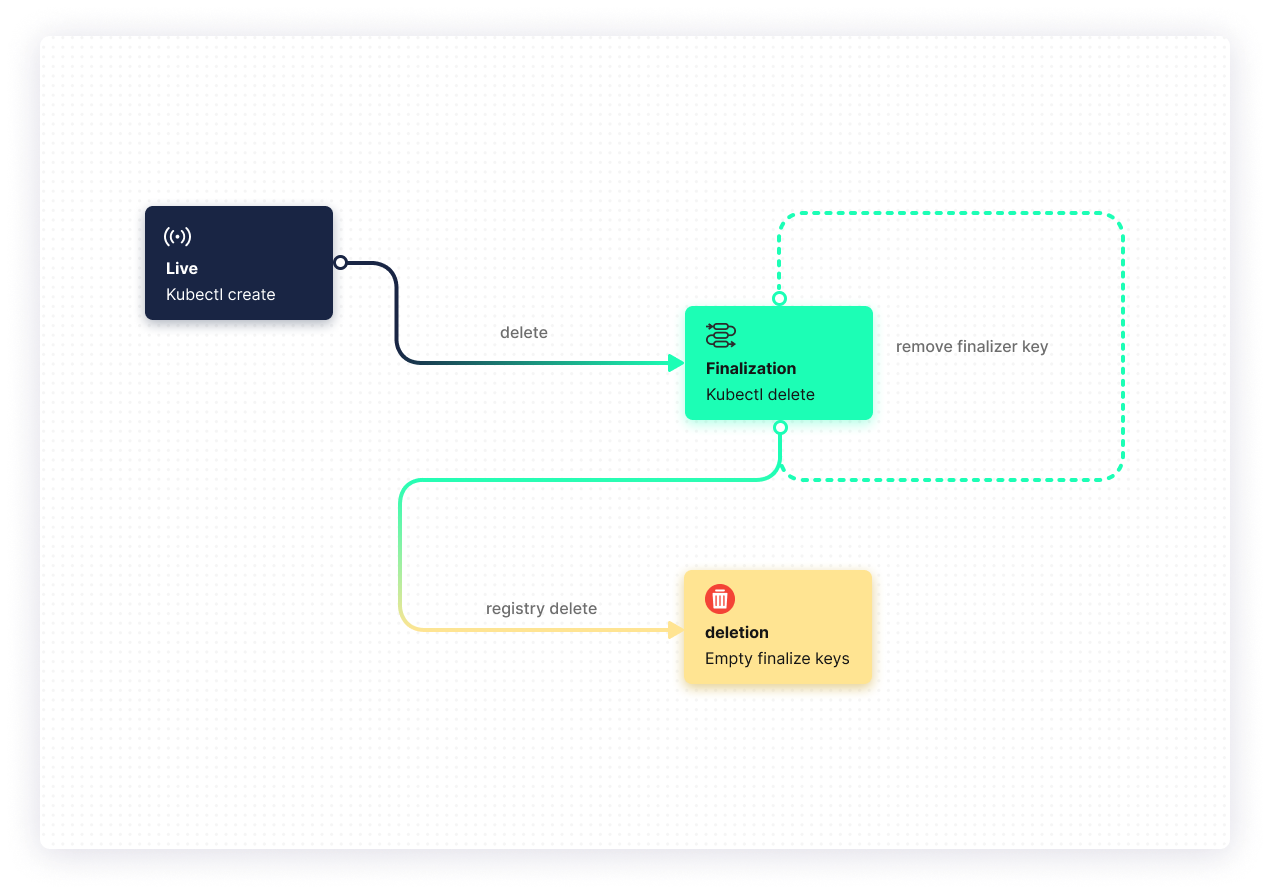
As you see, finalizers help delete your object, implement garbage collection, and prevent accidental deletions. They also notify the controller of removals. You can learn more about them here.
You can also create your own finalizers to delete objects, which sometimes get stuck in a terminating state. A good example would be this finalizer, which deletes your stuck namespace in one go.
Owners and dependents
Owners and dependents are a parent-child relationship present in Kubernetes. Take a look at the following deployment object manifest:
The deployment object has replicas and pods objects linked to it. Deployment is the owner of replicas and pods, and the pods/replicas are dependents of the deployment object.
If you delete the owner, the dependents get deleted too. So the owner objects manage the dependents automatically, and any change in them translates to a change in the dependent. The relationship is managed by a metadata field called ownerReference.
Recommended labels
Kubectl is not the only tool you can use to manage Kubernetes objects. There are dashboards, CLIs, and other tools that help you, and you can use one or a combination of them.
Recommended labels are a collection of labels that enable your tools to communicate with one another by describing items in a way that all of the tools can comprehend.
In the above example, you can see how we have added metadata labels that help to identify the required instance from our dashboard. You can select them and find all the objects related to your label.
In a production Kubernetes cluster, where thousands of objects are running, you need to manage them efficiently. Recommended labels are a suggestion from Kubernetes for efficiently standardizing the management of your objects.
Learn more about the recommendations here.
Final thoughts
Now that you’ve learned about Kubernetes objects, you can understand how important they are. Objects are one of your cluster’s fundamental units, and a good understanding of them will come in handy often. The best ways to learn more about them are to go through the official Kubernetes documentation and our blog.
If you're looking for a third-party solution to help you manage your Kubernetes applications, then consider using Airplane. Airplane is the developer platform for building internal tools. With Airplane, you can build single or multi-step operations and custom UIs within minutes for your engineering workflows. Airplane also offers strong out-of-the-box features, like job scheduling and permissions setting, that make it easy to manage.
Sign up for a free account or book a demo and start building powerful internal tools in minutes.


