PostgreSQL (or Postgres for short) is a powerful, open-source, object-relational database management system. Its robustness, scalability, and extensibility make it popular among developers. This article explores an underutilized feature of Postgres: variables.
Postgres has two types of variables that can be used to store and manipulate data: session variables and local variables. Session variables are defined at the session level and persist throughout the entire session, while local variables are only accessible within the context of a specific function or block. Both types of variables offer unique advantages and can be used to enhance the flexibility and efficiency of database usage.
By the end of this article, you'll have a better understanding of both session and local variables in Postgres, including how to define, use, and manipulate them. Additionally, we'll walk through some advanced use cases and best practices for working with these variables.
Explaining variables in Postgres
Variables provide several benefits that help users work effectively with Postgres databases.
One of the most important benefits is that variables help us organize and structure the code. They allow users to assign meaningful names to values, making SQL queries and PL/pgSQL code more readable and easier to maintain. Consequently, using variables to store and reuse values throughout the code reduces the chances of errors and makes it more concise. In this way, Postgres variables provide similar benefits to variables in other languages.
Variables also allow users to temporarily override Postgres configuration settings at runtime. This feature lets users adjust settings on a per-query basis.
Users encounter two types of variables in Postgres: local variables and session variables. The examples in the following sections explore each type in more detail. The examples assume we're writing to a log table created with the following SQL:
Local variables
Local variables are helpful when a user needs to store and manipulate data within the context of a specific block or transaction in the PL/pgSQL code. They provide a temporary storage location for data, making it easier to work with and process throughout a Postgres function, block, or transaction. Local variables can hold intermediate results, loop counters, or any other value needed for later use in the code.
Postgres has two types of local variables: transaction-local and block-local. They each use different syntax for setting and reading variable values.
SET LOCAL sets a temporary value for a configuration parameter or a user-defined variable that is valid only for the duration of the current transaction. Users can also set transaction-local variables with the set_config() function. SET LOCAL is more concise but only lets users set literal values like strings and numbers. We can use set_config if we need to concatenate strings or call Postgres functions to generate the value of the variable.
Either way, any variables set via SET LOCAL or set_config() must be prefixed by a custom namespace because Postgres uses the global settings namespace to store configuration settings. We'll walk through an example of this shortly.
In contrast, DECLARE defines a local variable valid for the duration of the current block or function. Unlike variables defined using SET LOCAL, variables defined using DECLARE can be used in multiple transactions inside the same code block, and their values persist until the end of the block.
Here's an example using SET LOCAL and set_config():
This example demonstrates some of the power of local variables. By storing log prefixes in variables, we avoid repeating actions and ensure a consistent prefix for all log entries.
Note that the example uses my_app as a custom namespace. Without this, Postgres would show us an error message for trying to set a nonexistent configuration setting.
The base log prefix is set using SET LOCAL since its value is a string. The info and warning log prefixes use set_config() because they call current_setting() to read the base log prefix and then use the || string concatenation operator. Either of those will cause an error if they are used in a SET LOCAL call.
The examples presented up to this point are useful, but what if we need to execute several transactions in a row and want to use a common identifier for them in our logs? In that case, transaction-local variables are not a suitable solution.
Fortunately, DECLARE can help. Note that DECLARE must be used inside a PL/pgSQL DO block, as in the following example:
This example uses local variables set with DECLARE to save common logging prefixes used across multiple transactions in a single code block.
Note that the gen_random_uuid() function generates a unique UUID for the session. This function is part of the pgcrypto module, which may need to be installed and enabled in the Postgres installation.
As the example demonstrates, we can create several variables in a single DECLARE block. Note that the := operator allows us to assign values to an already-declared variable.
Session variables
Session variables, on the other hand, store and manipulate data at the session level. A session starts when an authorized user connects to a PostgreSQL database and ends when the connection terminates.
Session variables can store user preferences, session-specific settings, or any other data that must be accessible across multiple transactions or functions within the same session.
Session variables are typically created and manipulated using the SET SESSION command and retrieved using the current_setting() function. Note that SESSION is the default when calling SET. Calling SET without LOCAL or SESSION afterward creates a session variable.
Deciding between SET and SET SESSION is a style choice; one might prefer the conciseness of SET or the explicitness of SET SESSION.
The code blocks in this section use the log table described earlier plus a person table with the following schema:
Here's how we might use session variables when inserting a person row into the database across multiple transactions in a single session:
Now, if we keep the database connection open, we can return later and run additional queries using the variables created, like so:
These examples show how users can easily set a session variable and reuse it across multiple transactions without recreating it.
To further clarify why a user might use session variables over local variables, consider how inserting data about people into the database as we did in the previous two queries might look in a real application:
This simple Python example represents a common use case that looks similar in other programming languages. It inserts several people into the database, each in a separate transaction.
Envision a scenario where we need to read multiple batches of people and write them in separate transactions, but we want to note that they were all written as part of the same workflow. Session variables provide an easy way to do that.
Going Further: Using Postgres variables with default values and SELECT INTO
As we've seen, Postgres variables help us avoid repetitive SQL and make database queries more readable. Although variables are useful on their own, Postgres has several features that help us use variables more effectively. This section explores two of the most important: default values and SELECT INTO.
Default values
When working with variables, we may want to set default values to ensure the code behaves predictably even when no value is assigned to the variable after creation.
Using DECLARE, we can provide default values during variable creation. If we don't provide a default value, the variable will be initialized with a NULL value.
As an example, we can simplify the previous local variable example by assigning defaults upon variable creation:
Variables created using SET always have a default value, since Postgres will not allow us to SET a variable without providing a value to set it to.
SELECT INTO
The SELECT INTO statement is another useful feature in Postgres. It allows users to store a primitive (such as a string or number) returned by a query directly into a variable. This can be particularly helpful when we need to process the results of a query within the PL/pgSQL code.
When using SELECT INTO, we need to incorporate it into a PL/pgSQL block or function. Here's an example of how we can use SELECT INTO to store the result of a query in a local variable:
In this example, SELECT INTO stores the sum of the price column from a sales table into the total_sales variable. We can then use the value of total_sales in a conditional statement to raise a notice if total sales exceed $100,000.
Mastering default values, configuration settings, and SELECT INTO helps users further unlock the power of variables in Postgres and write more efficient and flexible code.
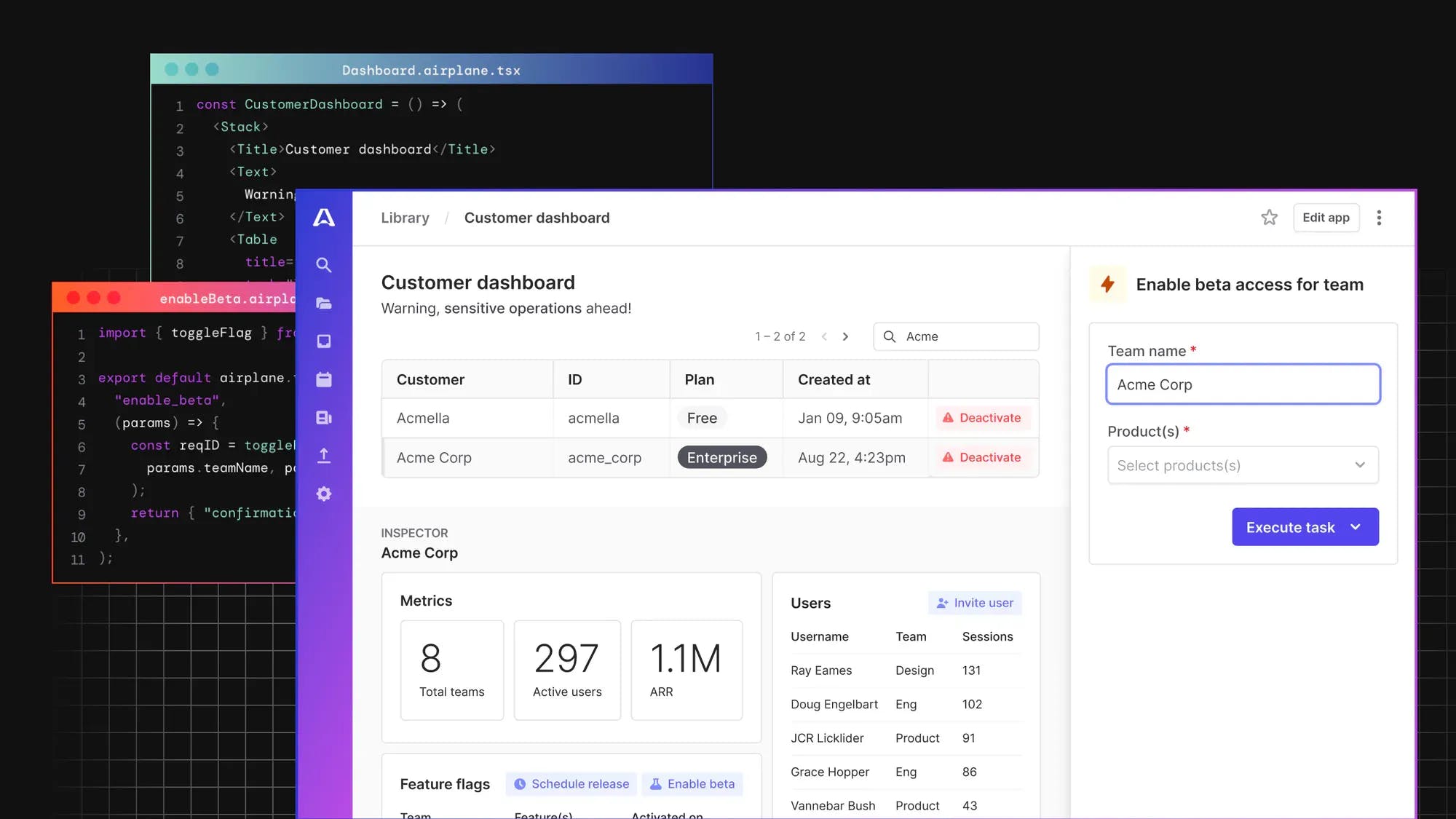
Introducing Airplane: Build robust UIs and workflows using code
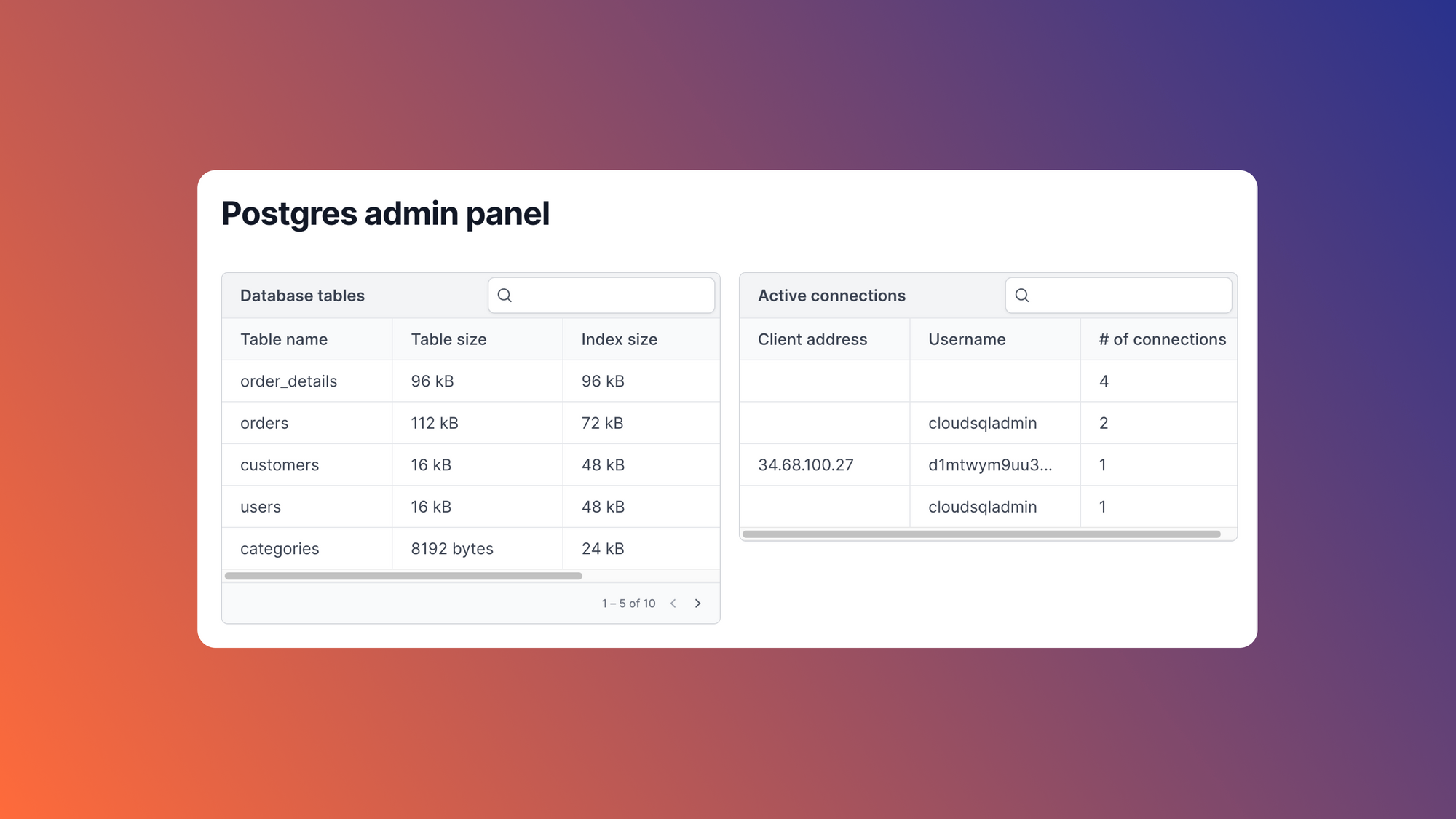
Airplane is the developer platform for building custom internal tools. You can transform scripts, queries, APIs, and more into powerful UIs and workflows. With Airplane, you can also quickly build React-based UIs called Views that connect to a PostgreSQL database. You can use Airplane's Postgres admin panel template to easily get started.
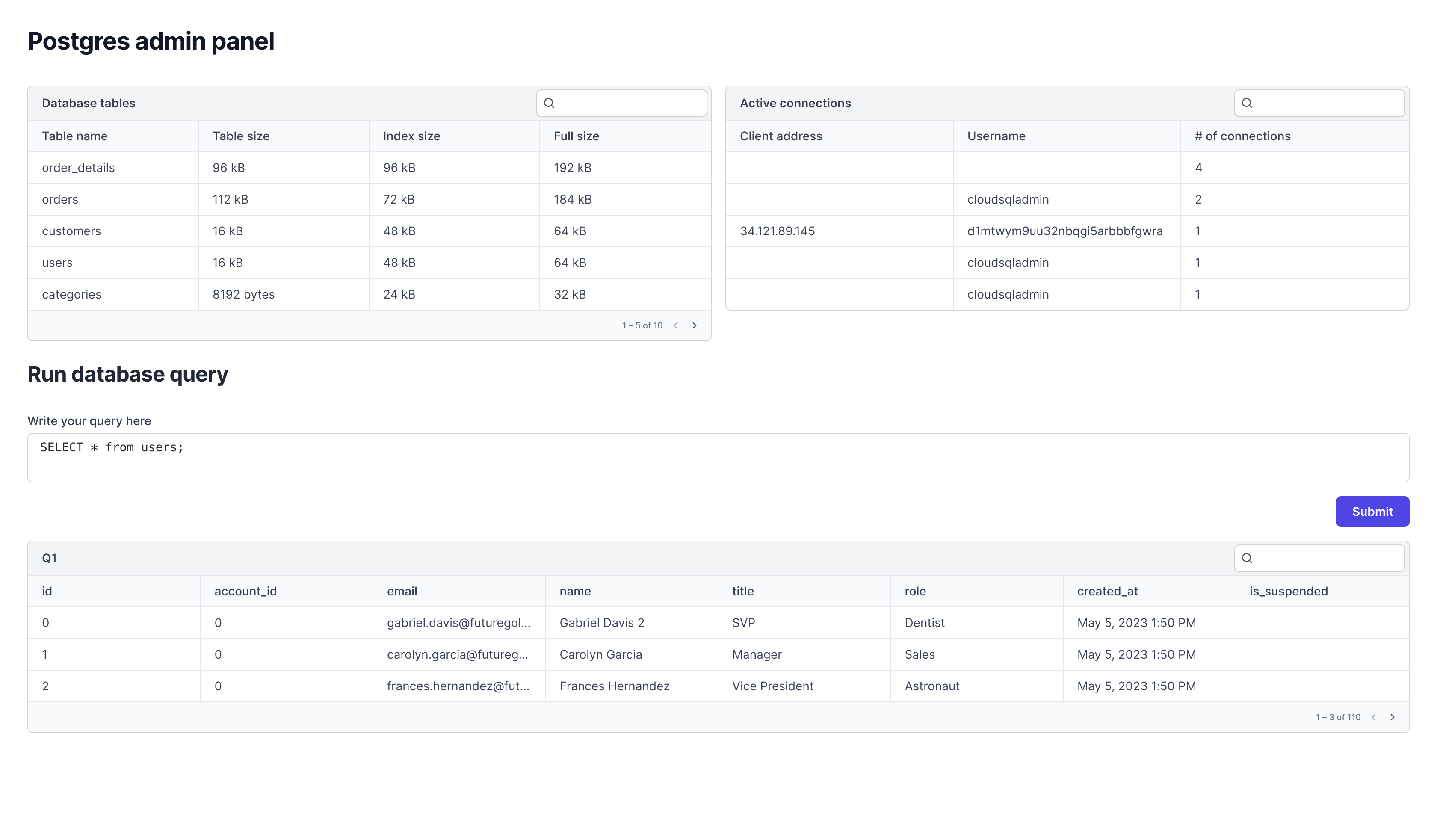
Airplane allows for complex customization of UIs through custom code. Users can implement a few lines of custom logic to create internal tools that fit their specific needs. Airplane also offers strong built-in capabilities, such as job scheduling, audit logs, permissions setting, and more.
To learn more about building PostgreSQL workflows and UIs, check out our blog for content such as how to build a Postgres GUI using Views, top 5 Postgres GUI tools, scheduling PostgreSQL jobs in Airplane, and more.
To build your first PostgreSQL dashboard within minutes, sign up for a free account or book a demo.
Author: Ryan Peden
Ryan has been a software developer for over a decade and a writer for five years. He is passionate about clean code, functional programming, and, most of all, finding ways to keep software development fun.