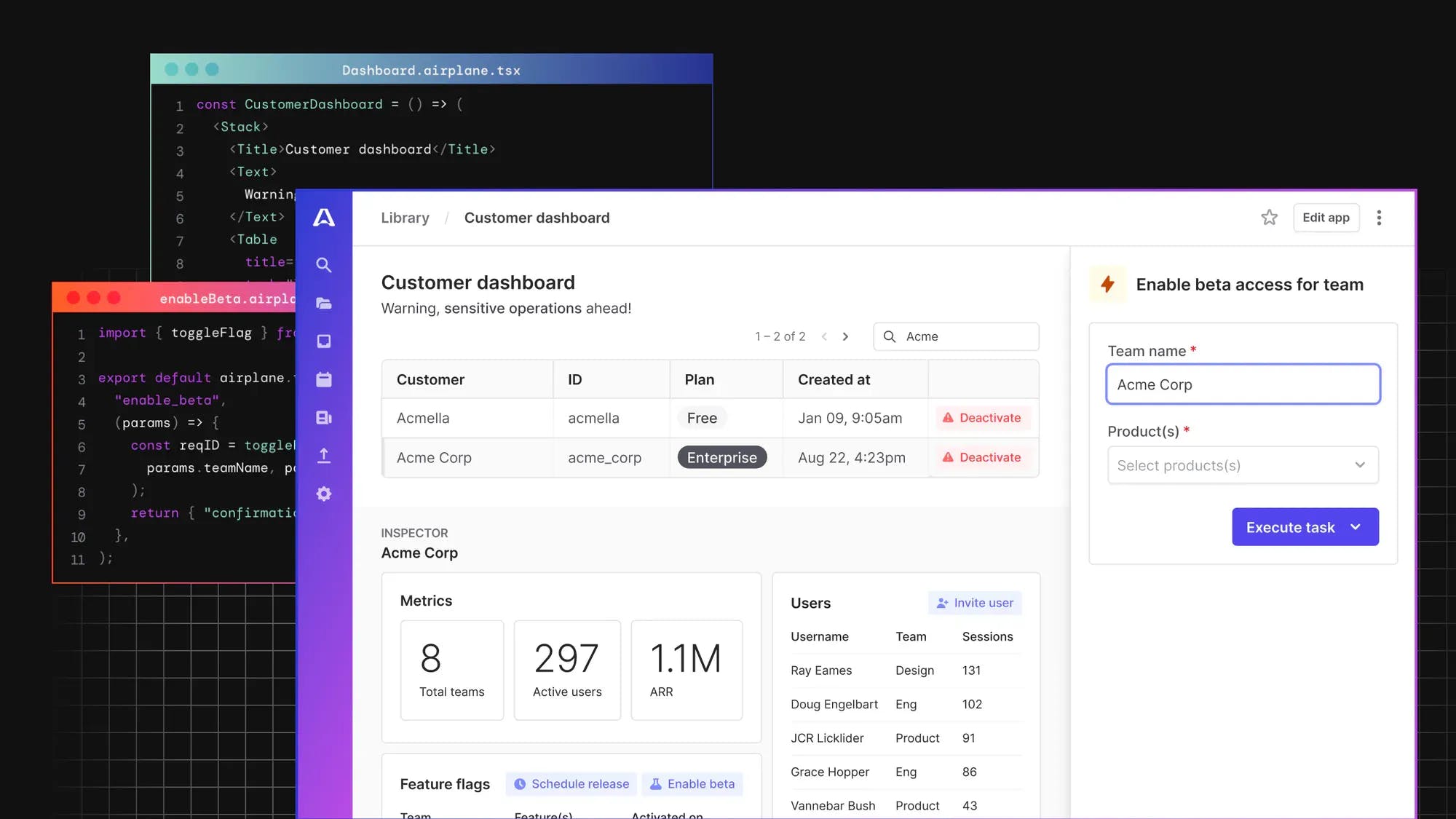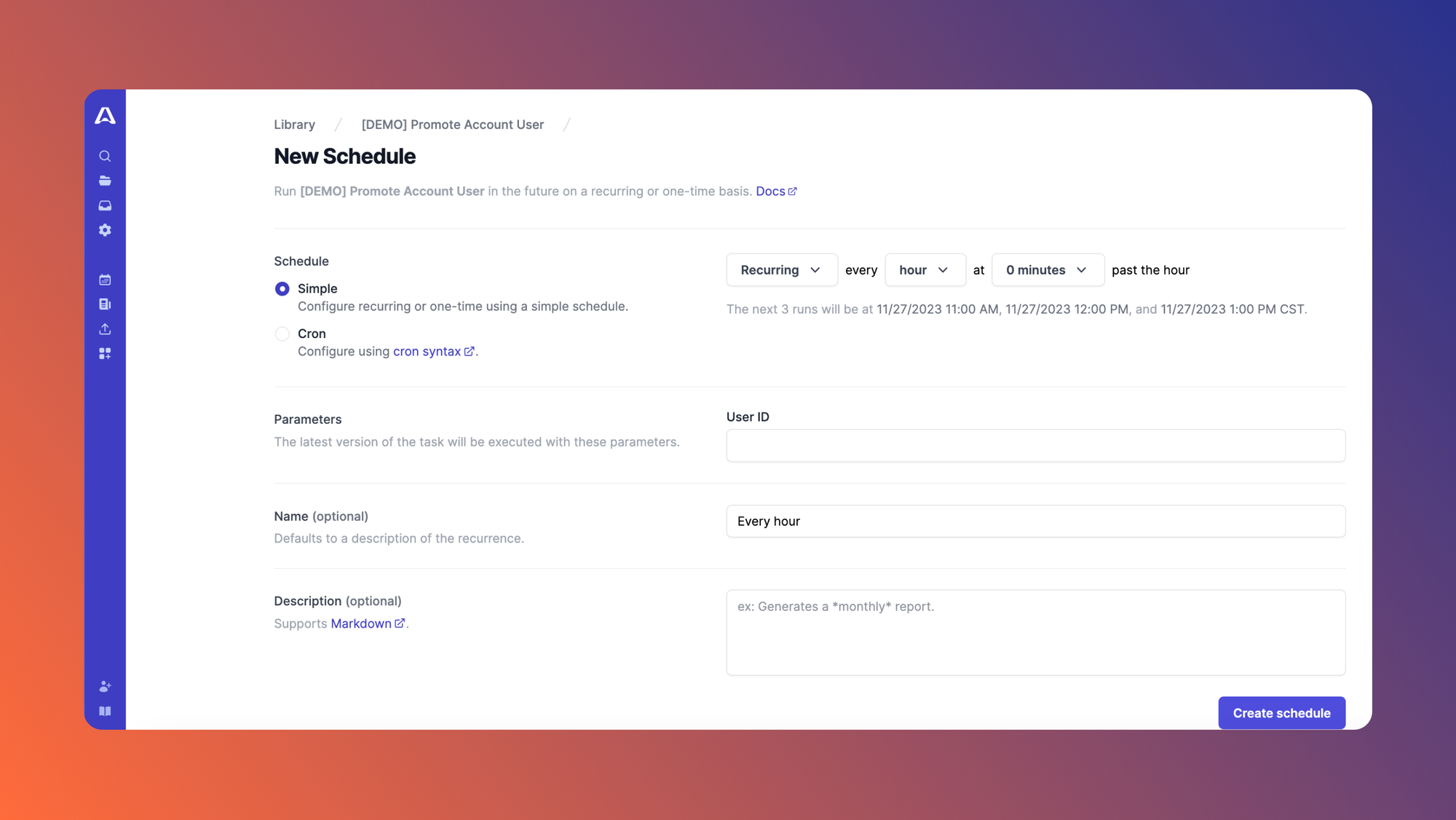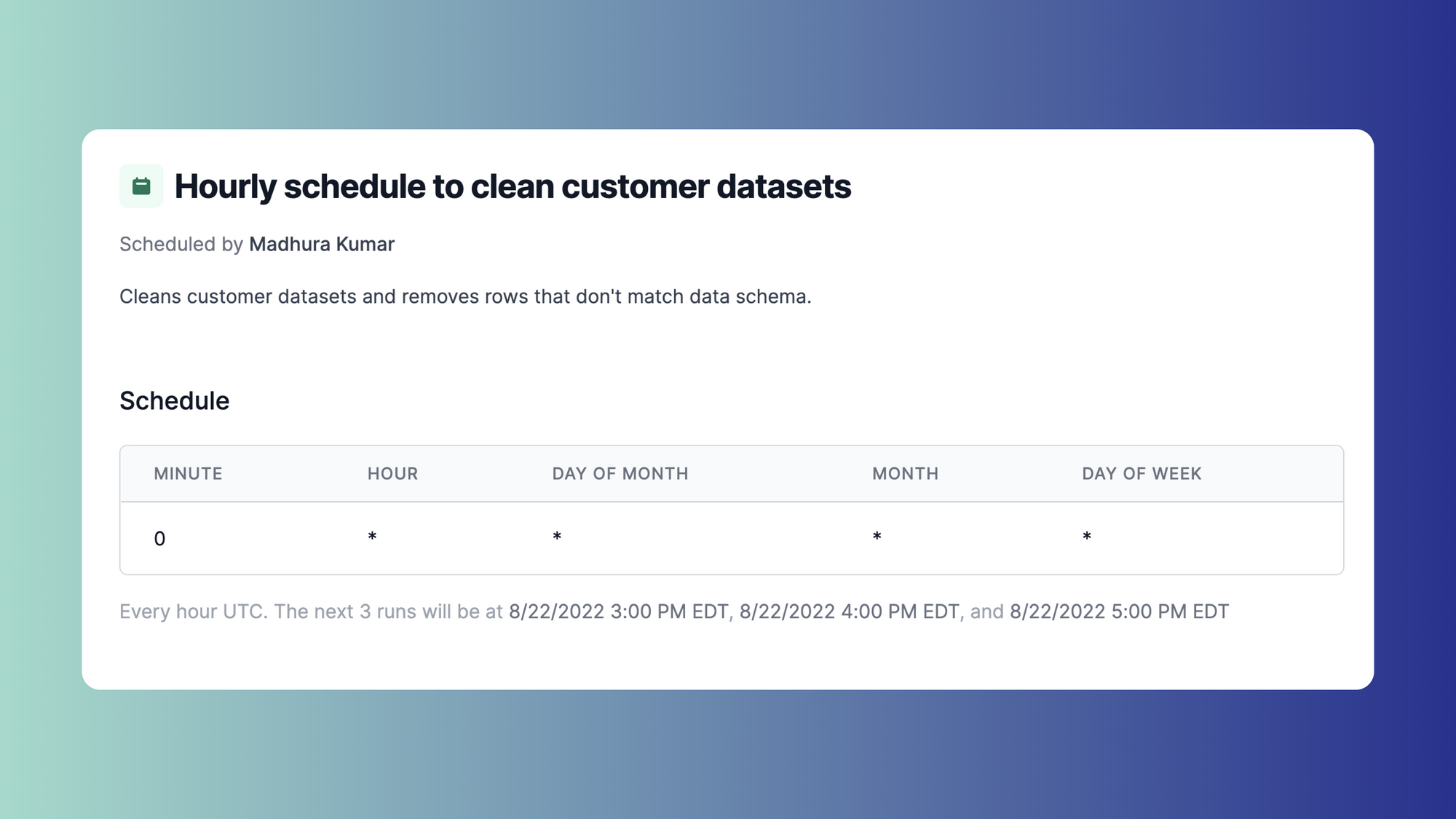
Most organizations pull data from different sources and formats making manipulation of datasets difficult without something like data automation. Data automation involves the use of technological tools to handle and manipulate data instead of doing so manually. Overall, the goal of data automation is to improve productivity within your organization. This process is useful for many roles within an organization from data scientists to engineers who help with database administration.
In this article, we'll walk through how to get started with data automation, cover some benefits and best practices, and walk through a few data automation tools that can help you get started.
What is data automation, and why do you need it?
Data automation is the process of applying automated processes and technologies for tasks requiring data handling, such as data extraction, transformation, and loading.
As mentioned, data automation helps to improve productivity around the use of data within your organization. Some primary benefits of data automation include easier data cleaning, improved data integrity, and faster data transformation. We go into each of these in more detail below.
Easier data wrangling
Data wrangling, also known as data cleaning, is the process of transforming a raw dataset into a format that is more suitable for data analysis. Examples of data cleaning include removing empty rows from your dataset, making the number of characters for entries consistent, and capitalizing the first and last names of individuals.
Often times the steps taken in data cleaning are repeatable and can be used as frameworks and standards for subsequent datasets that need to be cleaned. These steps can be automated using scripts and schedules to make new data match existing schemas and run the steps on a recurring cadence whenever new data is imported. You can also implement health checks to periodically check if the datasets are in the right formats.
Data integrity and error detection
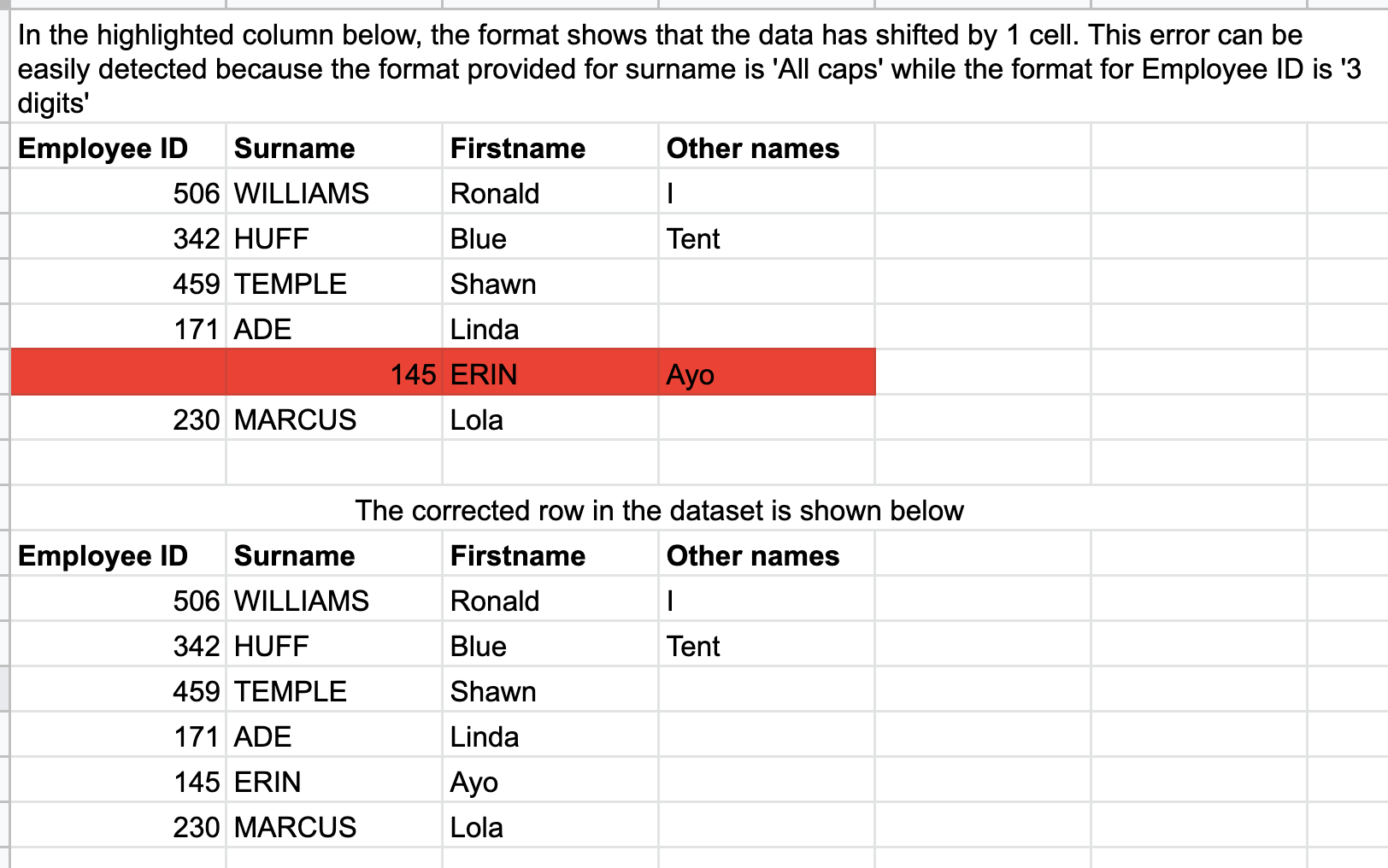
Since datasets are typically standardized according to formats and schemas, you can use data automation to detect and fix any records that don't match that format. For example, let's say all surnames in your dataset should be capitalized and all employee IDs should be three digits. A data engineer can automatically check for capitalized surnames as well as validate employee IDs to ensure they're three digits. Data automation helps improve data integrity and quickly detect errors. For example, you can then surface employee records missing a three-digit ID or having an invalid ID in an inbox.
Here's a visual depiction of the example above where Surname must be all caps and Employee ID must be three digits:
Faster data transformation
Data transformation is the process of changing datasets from one format to another. For example, you can change the format for dates in a dataset from one format like date/month/year to another like month name:
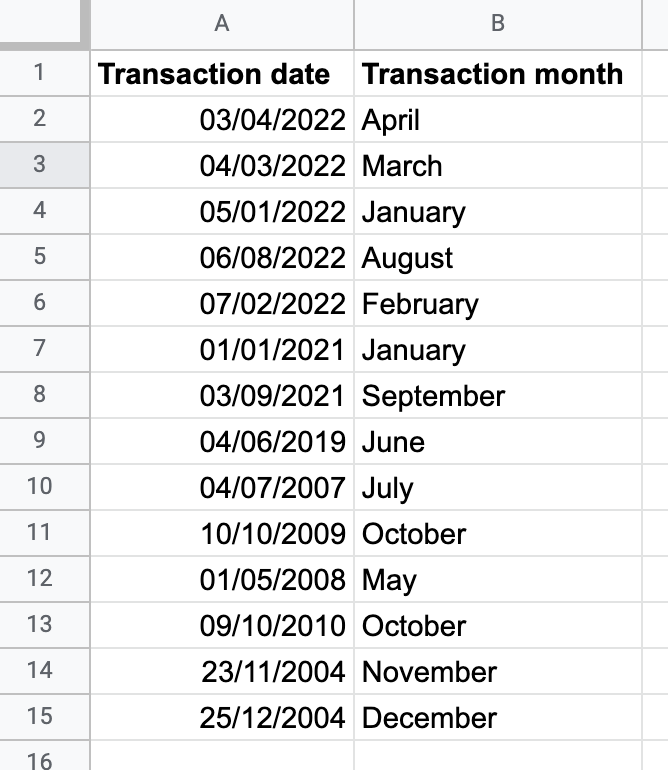
Data transformation involves checking the dataset to ensure it's in the right format in the destination repository, ensuring that there are no duplicates, and checking that the dataset follows your set standards. This helps speed up downstream processes because when you need to transform, manipulate, or analyze the data afterwards, it's already in a standardized format.
Other benefits of data automation
Outside of the three larger reasons described above, there are a couple of other general benefits of data automation:
- Reduced operational costs: Data automation can lower operational costs by reducing the resources an organization needs. For instance, an organization may only need to employ the services of a data engineer for a one-off data-automation setup. The process can then run unattended once it is up and running.
- Improved productivity and growth: Automation requires little or no human intervention and enables you to execute processes more efficiently and quickly. This means that engineers and data scientists within the organization can focus on streamlining other tasks as well as contribute to building new features. In the long run, this will make teams more productive as well as promote company growth.
- Faster analytics: When data automation is utilized for analytics, data engineers can transform data into insights via dashboards more quickly and accurately. Automation also support more real-time results. For example, when using Power BI, you can schedule your datasets to refresh daily so at any given point in time you're looking at the latest information.
Now that we've discussed the basics of data automation and its benefits, let's dive into how to actually get started with it.
Getting started with data automation
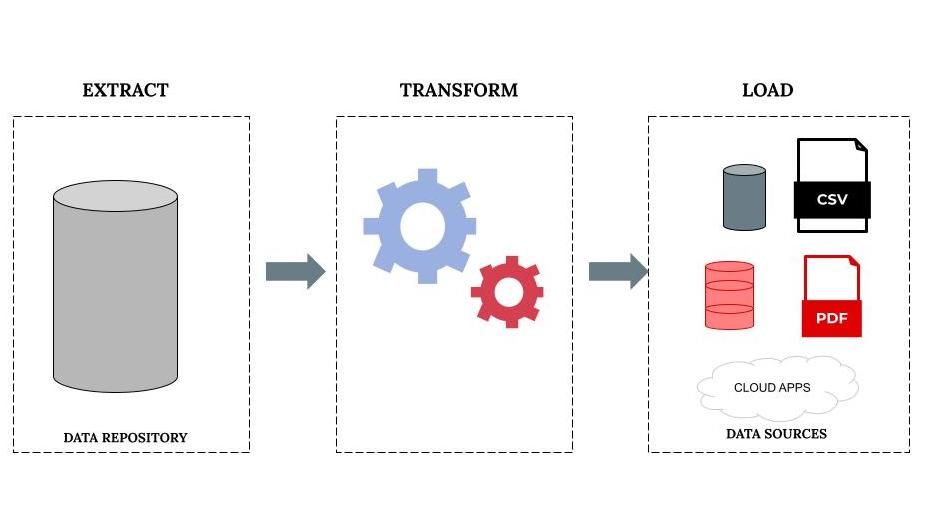
There are three primary steps in data automation: extraction, transformation, and loading (ETL). We describe these in more detail below:
- Extraction (E): Extraction is the process of gathering datasets from different sources. These sources can include things like customer databases, marketing files, customer transaction records, and flat files. Flat files store records in a plain text format and store one record of data per line. Examples are CSV and Excel files.
- Transformation (T): Transformation involves converting data into a standard format for use in a destination repository or data warehouse. This stage involves several data subprocesses including cleaning, standardization, deduplication, verification, and quality management. We'll discuss these subprocesses in more detail in the following section.
- Loading (L): In this stage, you load the transformed datasets to your data repository. The data repository can be a database or a data warehouse. These datasets are usually in a different format from their source datasets since they've gone through transformation processes.
Transformation subprocesses
As mentioned above, the transformation step in data automation involves several subprocesses. Here are a couple of those subprocesses in more detail:
- Cleaning: Cleaning is used to identify and remove any inaccuracies in datasets, such as fields left blank (nulls) or spelling errors. For example, cleaning would catch if someone entered "yelow" instead of "yellow".
- Standardization: Ensures the data has a standard format—for example, ensuring that all US customer mobile numbers are eleven digits and have “+1” as a prefix.
- Deduplication: Ensures that there are no duplicate copies of data. This saves storage space and bandwidth which reduces costs.
- Verification: Verification helps engineers check datasets for inconsistencies and detect errors as early as possible. An example of an inconsistency might be entering text instead of numbers into a field or using a combination of abbreviations and full words in records. For example, using the letter “O” instead of the digit “0” in a phone number or recording “New York” as “NY” under the “State” column for some records and “New York” for others within the same table in a database. You can see these examples in the following image:
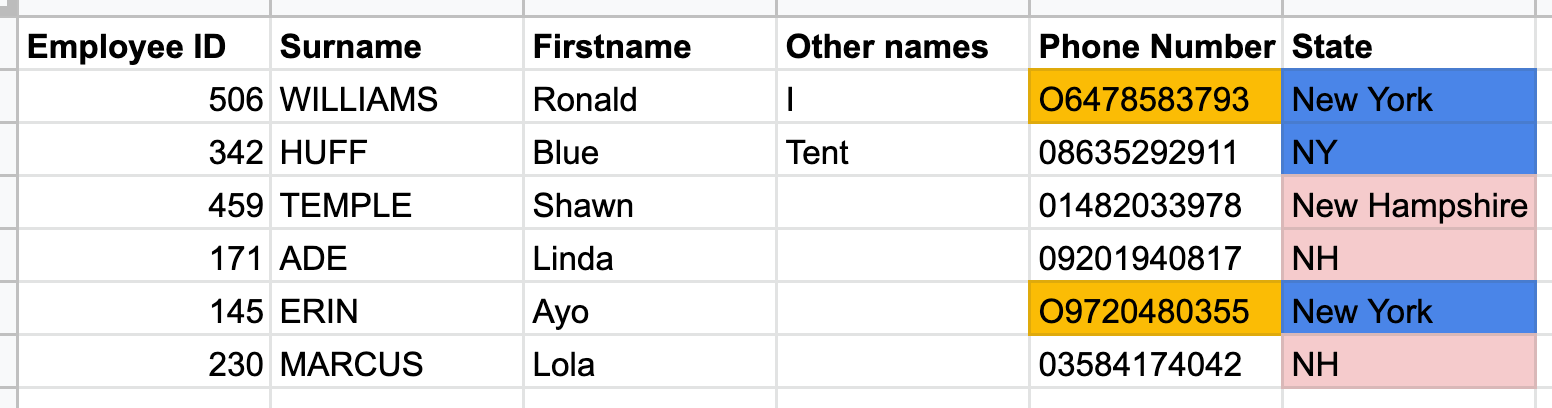
5. Quality management: Organizations typically define their own requirements for data quality and reporting. Quality management helps ensure that your data meets these requirements. For example, all email addresses in a database are automatically checked to ensure they follow the standard format local-part, @ symbol, and domain name.
ETL Flavors
There are a few different flavors of ETL and the steps don't necessarily always follow the same order of extraction, transformation, and then loading. These steps can be implemented in different ways depending on your data pipeline. Let's walk through a few different ETL flavors below.
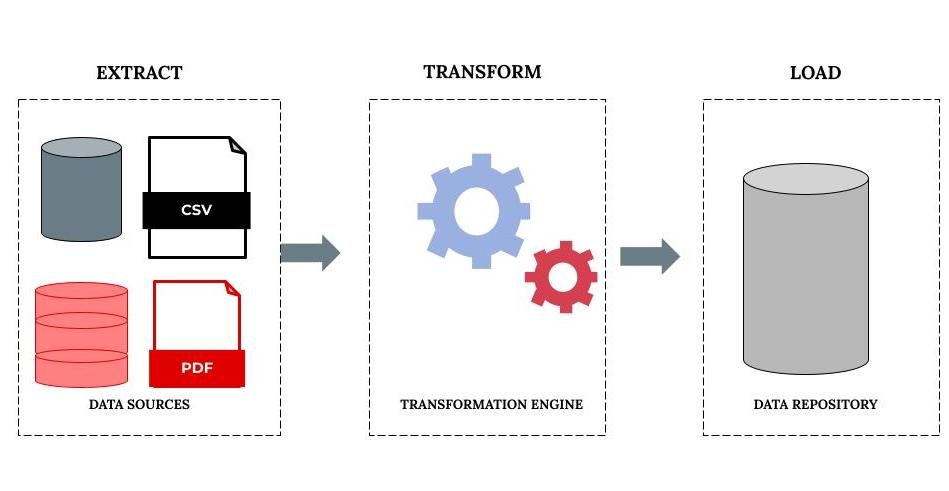
- ETL: In some data pipelines, the data automation stages take place as described above—extract, transform, and then load. When this happens, the transform stage is executed using a transformation engine. Some ETL tools like Microsoft SSIS run these three stages in parallel, which can save time. The diagram below shows this process:
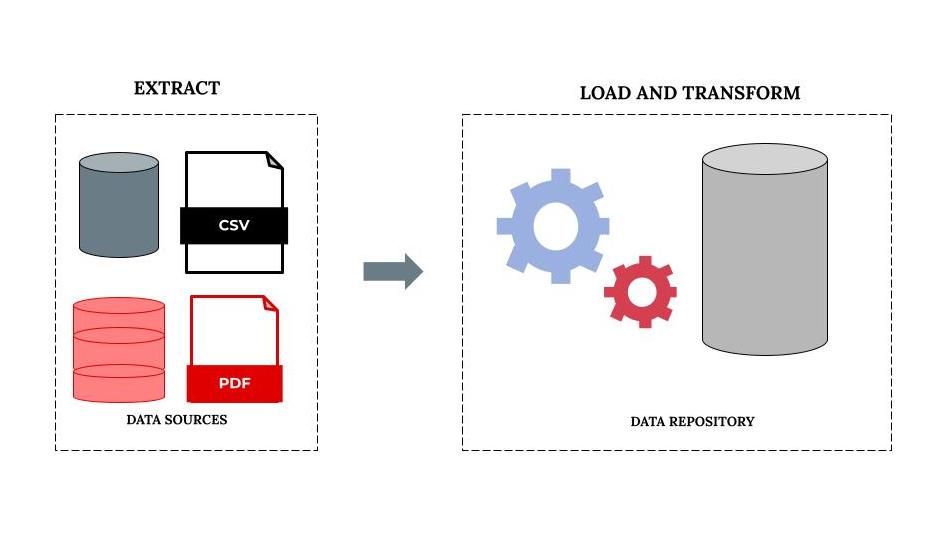
- ELT: In some pipelines, data automation takes place in the order extract, load, and transform (ELT). In this case, data transformation occurs when the data is in the repository of the destination database or data warehouse. This method can be advantageous for driving data efficiencies and saving time. This is because, unlike ETL, this method does not include copying the dataset into a transformation engine after extraction. The diagram below shows the ELT process:
- Reverse ETL: This is the process of copying data from your single data warehouse into different data repositories such as marketing platforms and cloud applications. The main reason for this method is so that engineers and data scientists can take action on the insights directly from datasets. The diagram below shows the reverse ETL process:
Now that we've walked through data automation and how it works, let's discuss some best practices.
Data automation best practices
Here are some best practices to ensure that your datasets are always up-to-date and meet the standards set during data transformation.
- Use reusable code: When transforming your dataset, we recommend using reusable scripts and queries. For example, when you automate your dataset to transform your "Date created" column to "Month", if it's not hard-coded or overfit, you can reuse that script for future datasets that are loaded from other data sources. If you overfit scripts, you won't be able to reuse them and will waste time writing new ones.
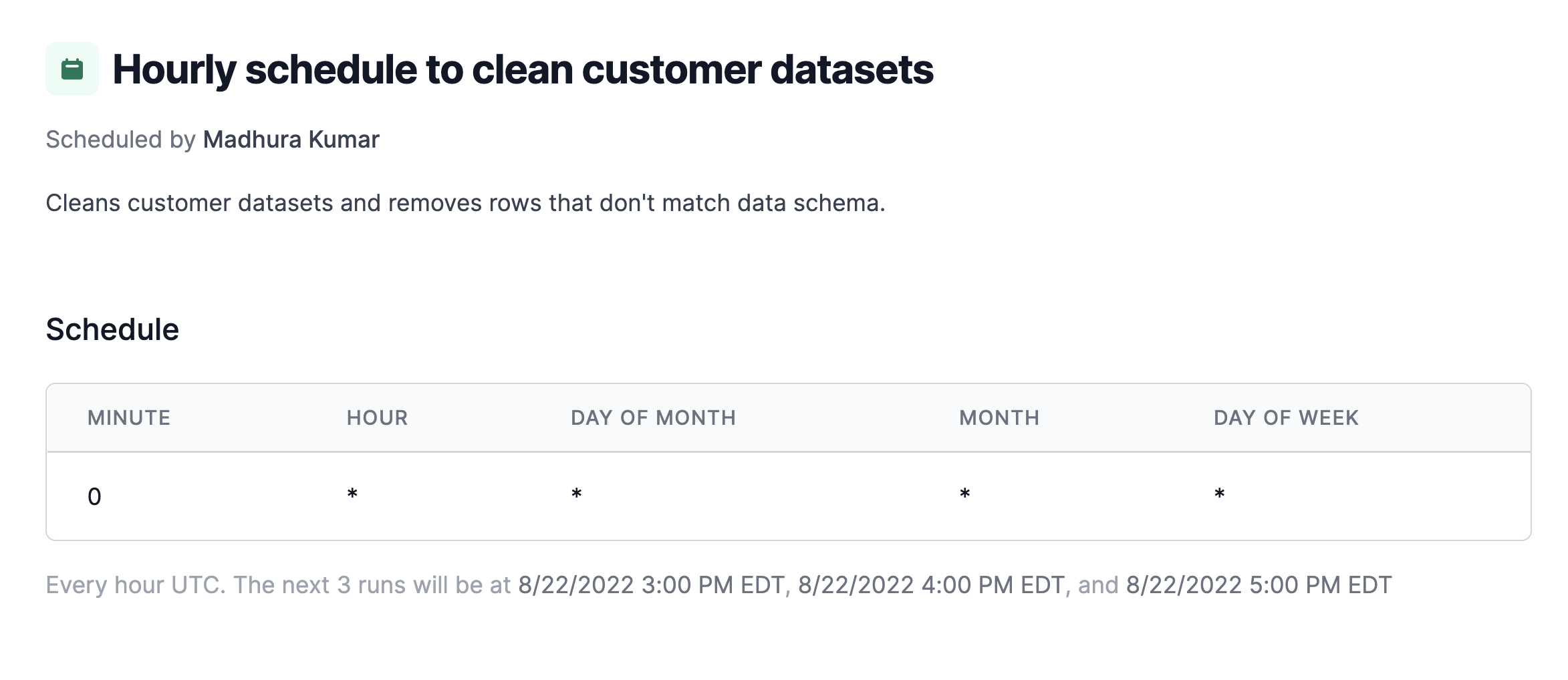
- Schedule updates: It's best to make sure your datasets are updating on regular cadences. For example, if you comb various data sources for information for a weekly report, you'll want to schedule a weekly data refresh.
- Implement a data governance policy: You'll likely want to implement a data governance policy on the automation process during the data transformation phase. This policy ensures a standardized process for data gathering, cleaning, and verification and ensures repeatability. This document should also include the steps needed to ensure quality management. Implementing this policy will help ensure you meet strict standards going forward, saving you time in the long run.
Now that we've discussed a few best practices, let's walk through some commonly-used tools for data automation.
Data automation tools
There are a variety of tools that can be used for data automation. In this section, we'll walk through four common data automation platforms and what they're used for: Microsoft SSIS, Oracle Data Warehouse, Amazon Redshift, and Airplane.
- Microsoft SSIS: SSIS stands for SQL Server Integration Services. SSIS is an integration service developed by Microsoft that can be used to execute a wide variety of data migration tasks and to perform the ETL process. The idea with SSIS is to make it easy to move data from one database to another. SSIS can also be used to extract data from sources such as SQL Server, Excel files, and Oracle. Some of the primary uses of SSIS include merging data from various sources, automating admin functions and data loading, and helping you clean and standardize data.
- Oracle Data Warehouse: Oracle Data Warehouse is a cloud-native data warehouse service. One of its goals is to eliminate the complexities of operating a data warehouse including automation of providing, configuring, scaling, and backups. This tool is unique because it offers more than one deployment option to meet your exact needs. The deployment options include: Shared Infrastructure, Dedicated Infrastructure, and Cloud@Customer. For instance, the Cloud@Customer allows users to handle and manipulate data on the cloud and pay per use.
- Amazon Redshift: Redshift is also a cloud-based platform used to perform data automation on large datasets. The platform is developed by Amazon and comes with strong data security features. Some of these features include end-to-end encryption and audit logs. Additionally, it allows engineers and data scientists to easily connect to business intelligence tools for data analysis.
- Airplane: Airplane is a developer platform used to quickly build internal applications and automate workflows. The basic building blocks of Airplane are Tasks, which represent single operations like syncing a dataset, restarting a microservice, or taking a database backup. Airplane lets you transform data engineering operations such as SQL queries, REST endpoints, and scripts into reusable applications for your team. For example, you can create an Airplane Task to "Clean datasets." You can then share this Task with anyone on your team and layer on approval flows for added security and schedules to run ETL processes on recurring cadences.
Airplane’s flexibility and range of supported features also make it the perfect tool for simple to complex data automation use cases. It's flexible in the sense that you can implement whatever backend logic you think is best for an operation via code. Then, Airplane layers on a UI, schedules, audit logs, role-based access controls, approval flows, input validation, and more so that you can set up enterprise-grade workflows in just minutes. In addition, Airplane runbooks combine the power of automation with the flexibility of user-defined apps, allowing you to integrate apps such as databases, Slack, email, REST APIs, and custom code. For example, when Airplane is integrated with Slack, team members can receive notifications, approve requests, and execute runbooks all from Slack.
Here's a quick summary of the tools we just discussed:
| Feature | Microsoft SSIS | Oracle Data Warehouse | Amazon Redshift | Airplane |
| On-premises vs cloud-based | On-prem | Cloud | Cloud | Cloud |
| Relational database management system (RDBMS) vs. Non-relational DBMS | RDBMS | RDBMS | RDBMS | Can handle both RDBMS and non-relational databases. For instance, SQL which is relational and REST which is non-relational |
| Data security | Features: SSIS logging, digital signatures, and access control for sensitive data available | Features: virtual private database (VPD), fine-grained auditing, and encryption | Features: load data encryption, access management, SSL connections and sign-in credential | Features: audit logs, role-based access controls, self-hosted agents, encryption, and SSH tunneling |
| Supported languages | Visual Basic, .NET, and C# | C, C++, Java, COBOL, PL/SQL, and Visual Basic | PSQL and Amazon Redshift RSQL | SQL, REST, Node.js, Python, Docker, Shell |
| Alerts and notifications | Requires a third-party tool like Zapier | Uses webhooks | Requires a third-party tool like Zapier or integrate.io | Can receive alerts via Slack and email automatically. Native Slack integration exists |
Get started with Airplane
Data automation helps engineers and data scientists reduce operational costs, create more efficient analytics, and detect errors in critical dataset more quickly, among many other benefits.
While there are several tools you can use when it comes to data automation, Airplane is a developer platform that offers a ton of flexibility with a seamless DX. Using Airplane you can clean and transform data, build out customer onboarding workflows, develop admin panels, schedule operations, automate one-off scripts, and so much more.
If you're interested in trying out Airplane, you can sign up for a free account or say hello at [email protected].
Author: Temilade Adefioye
Aina Temilade has Bachelors degree in Computer Science and a Masters degree in Information and Knowledge Management. In her role as a data analyst, she worked with cross-industry clients and helped design and create a variety of data analytics solutions.