Structure is essential in any system, and databases are no exception. Since their introduction in the 1970s, SQL databases have provided this structure via a strict data model that minimizes redundancy. However, over time, data storage costs have decreased and data volumes have increased. By the mid-2000s, there was a need for a different kind of database with a more flexible schema and better scalability, and NoSQL databases emerged to fulfill these needs. MongoDB is one of the most popular examples of this type of database.
MongoDB makes it easy for developers to build highly available and scalable applications. It uses the scale-out strategy, which allows many smaller computers to work together and allows you to add new computers when more capacity is needed. MongoDB stores data in documents, a form similar to that of JSON objects.
Aggregation in MongoDB is the process of compiling relevant information from the database's documents using computations. The MongoDB aggregation pipeline is a powerful and adaptable framework that allows you to perform data manipulation and aggregation tasks within the database without using external data processing tools. This pipeline, like most others, processes documents in stages. Before passing the documents to the next stage, each stage performs one or more operations. These operations could include filtering, grouping, projecting, sorting, and joining. The aggregation pipeline is also horizontally scalable and designed to be efficient and performant, allowing you to perform advanced analytics on large amounts of data with minimal latency.
In this article, we'll explore MongoDB aggregation pipelines and their typical stages. We'll also discuss some scenarios where these pipelines are useful and how to implement them.
Common pipeline stages
In MongoDB, aggregation pipelines can be run on the database itself or the collections within it. A collection in MongoDB contains related documents and is analogous to a table. This section explains three of the most common pipeline stages:
$matchstage$groupstage$sortstage
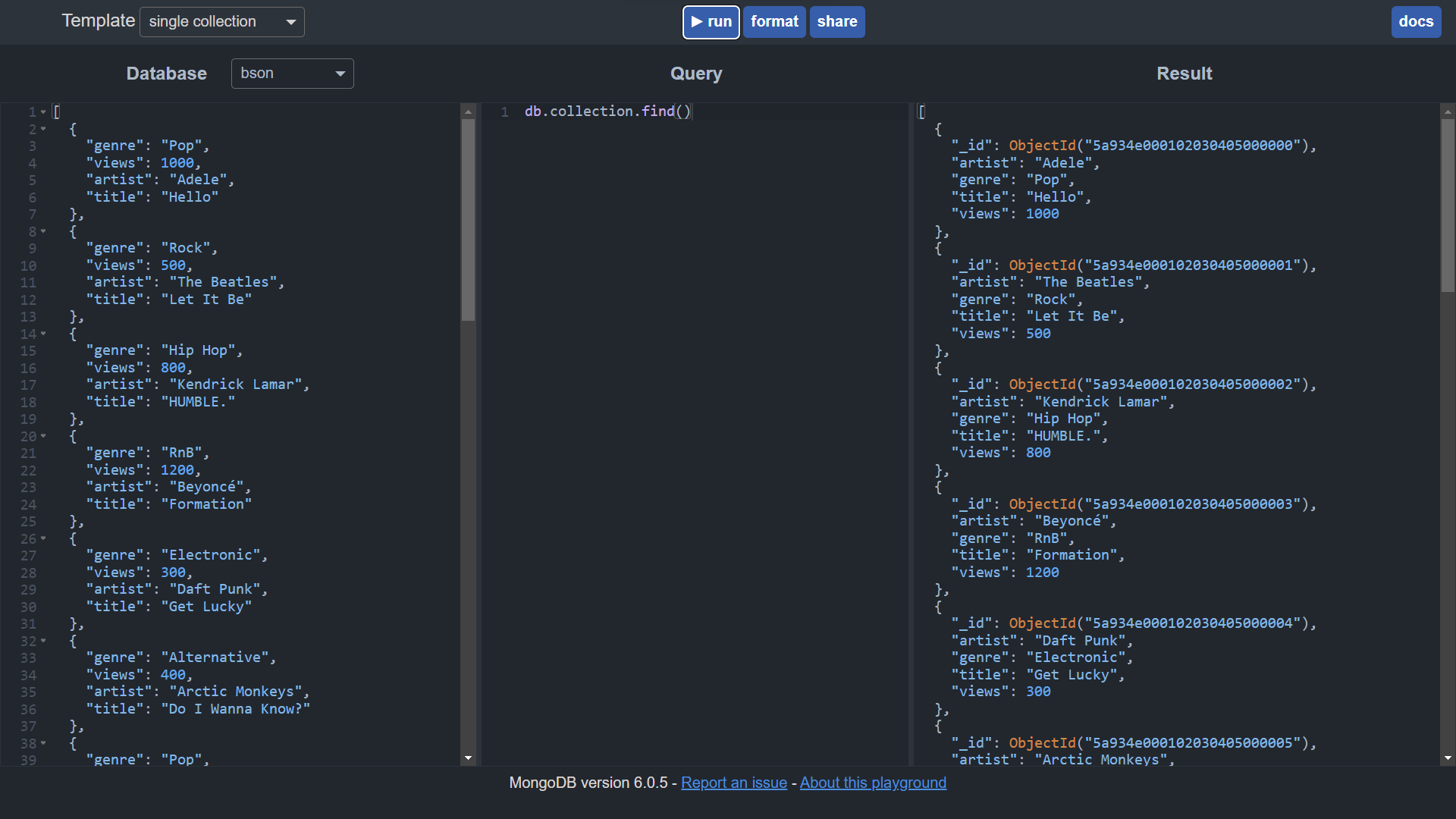
To facilitate the discussion, the Mongo playground is used to run queries on documents in a demo database that contains metadata about music videos.
Copy the contents of the database into the left pane of the Mongo playground before proceeding:
$match Stage
The $match stage is analogous to the IF statement in programming. At this stage, one or more conditions are specified. To pass through this stage, a document must meet these conditions (return True). Documents that do not match are excluded from the output for the following stage, making this stage essentially a filtering operation. As a result, the $match stage should be placed as early in the pipeline as possible to reduce the number of documents to be processed.
When used at the start of a pipeline, it can take advantage of indexes. This makes the operation more efficient because indexes store a small portion of a collection's data set and allow the database to search for them instead of scanning the whole collection. The following is a sample aggregation pipeline with a $match stage:
The query here is an equality match and only documents with a genre field that corresponds to "Pop" will be retained. The output from this is shown below:
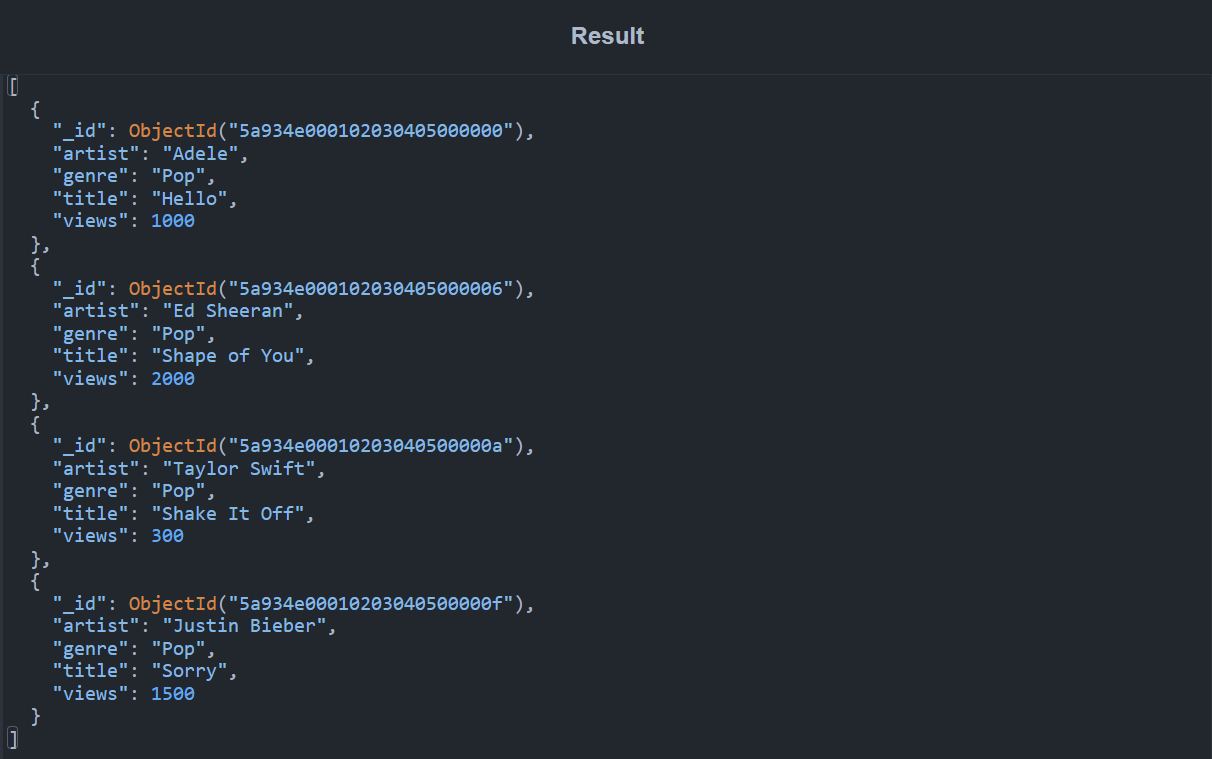
The following is another example of a query with a $match stage:
In this query, only documents that have a views field with a value greater than or equal to 1000 will be passed to the next stage. The output documents are shown below:
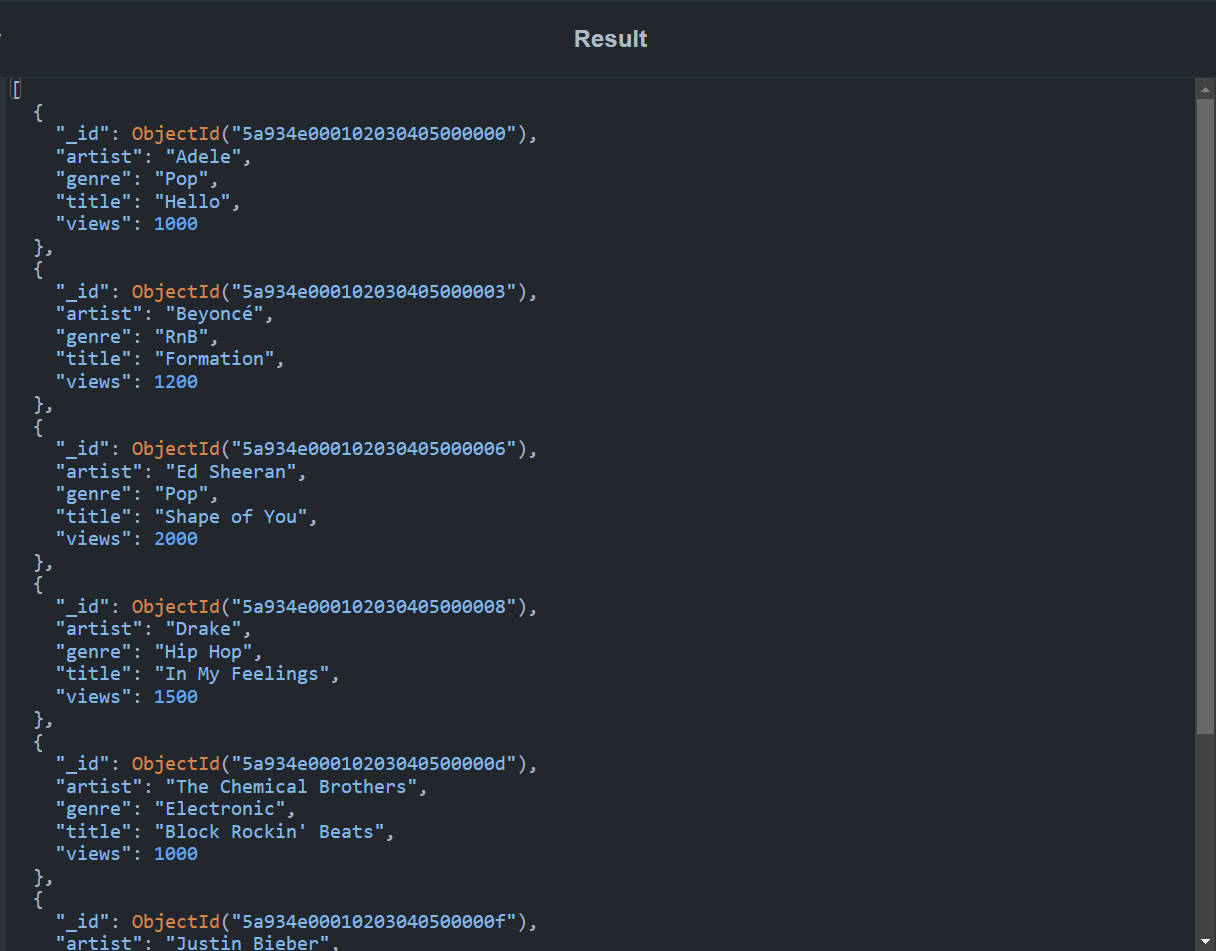
$group Stage
The $group stage is a document classification operation that uses an identifier to group documents based on a common attribute. This identifier can be a field, a group of fields, or the result of an expression. Once the identifier is applied, each resulting group corresponds to a unique identifier value and contains all the documents that share that value. However, only the identifiers are returned by default at this stage. If the identifier is set to null, all documents that reach the stage are grouped together. In addition, if an accumulation operation (such as summation or average) is specified on the documents in each group, the result is computed and returned along with the identifier.
The following is an example aggregation pipeline with the $group stage:
The genre field is specified as the identifier in this query, so the output will be a list of documents, each containing a unique genre. In addition, an aggregation expression is specified here to obtain the total views of all documents in each group. The $sum operator is used to perform this calculation, and the result is displayed in the totalViews field. The result of the query is displayed below:
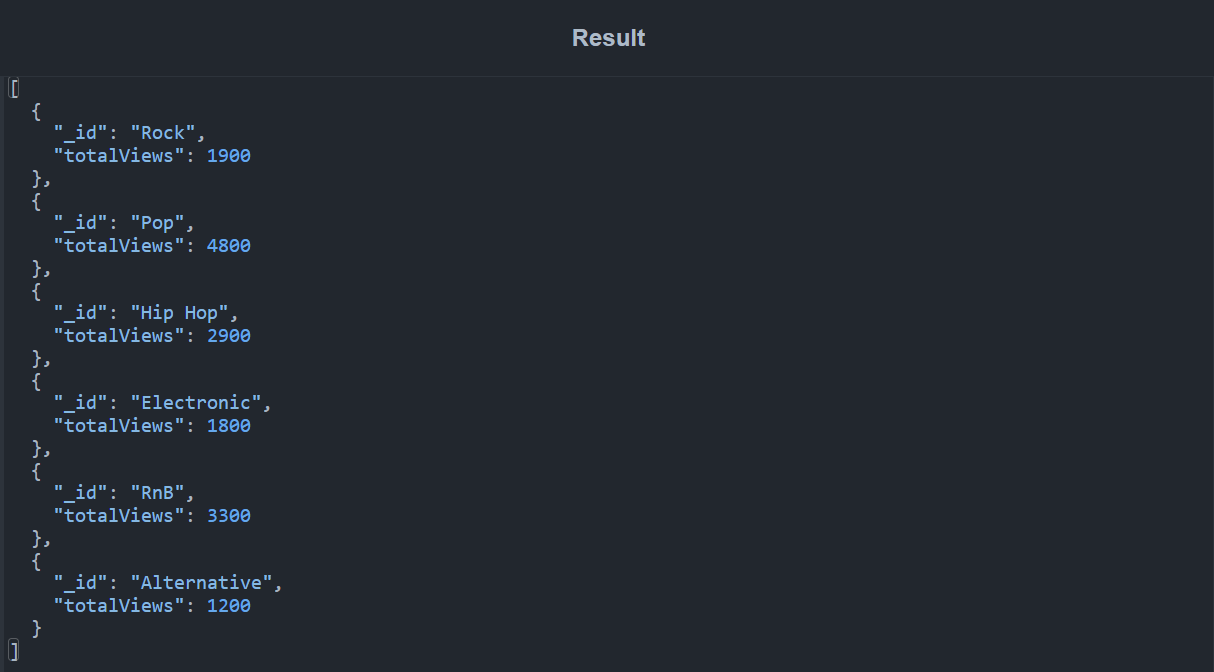
$sort Stage
The $sort stage literally sorts the input documents in the order specified by a key. This key could be a single field or a group of fields. Each field's sorting direction is indicated by a 1 for ascending and a -1 for descending. When more than one field is specified, the sort order is evaluated from left to right. For example, when sorting video metadata by genre and views, MongoDB sorts by genre first, then by views within each genre, as shown in the sample $sort stage query below:
In this query, the genre and views fields are passed to the $sort stage. The documents are first sorted by genre in ascending order, then by the number of views in descending order. A snippet of the output is shown below:
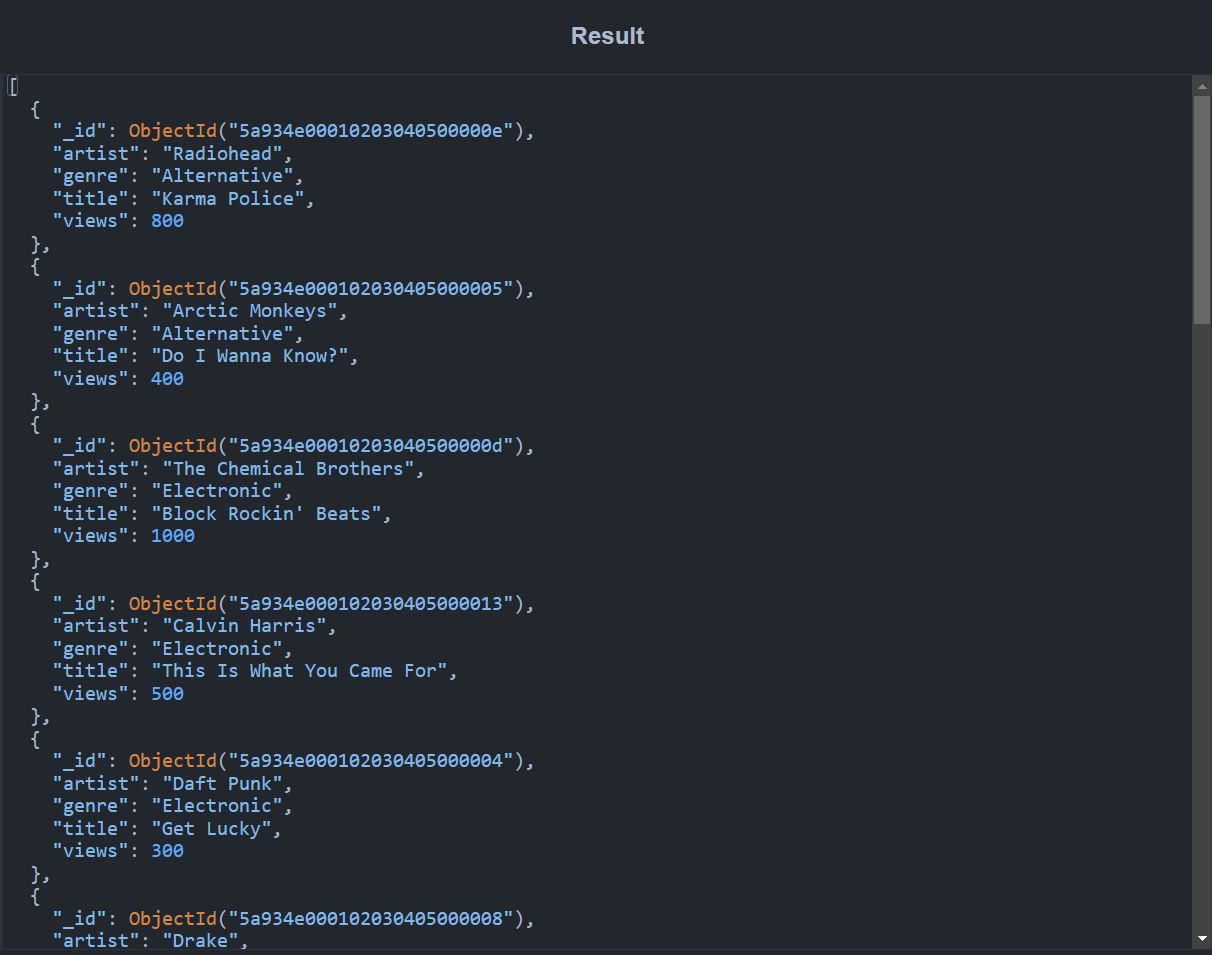
Aggregation Pipelines in the Real World
The following is a useful case study to demonstrate an aggregation pipeline in the real world. Consider a video streaming company with a database of documents containing metadata from music videos, similar to the database used previously. However, for this example, the database includes more fields and documents.
Return to the Mongo playground and copy the contents of this database into the left pane of the interface.
The streaming company wants to determine the most popular artists with videos longer than five minutes. To obtain this information, they formulate the following question: "Who are the top five artists with the most views and an average video duration longer than five minutes?"
We can input the following query in the central pane of the Mongo playground to answer this question:
In this query, we first use a $match stage to exclude all tracks with durations of less than five minutes. This query is used at the beginning to reduce the number of documents processed and speed up operations. The documents are then grouped by artist on the $group stage. In this stage, we also aggregate the total number of views for each artist and compute the average duration of their tracks. After that, we add a $sort stage to arrange the documents in decreasing order of total views, followed by decreasing average duration. Finally, we use the $limit stage, which is another filter stage that simply truncates the number of documents in the output to the specified amount (in this case, 5). The output below is obtained when this command is run:
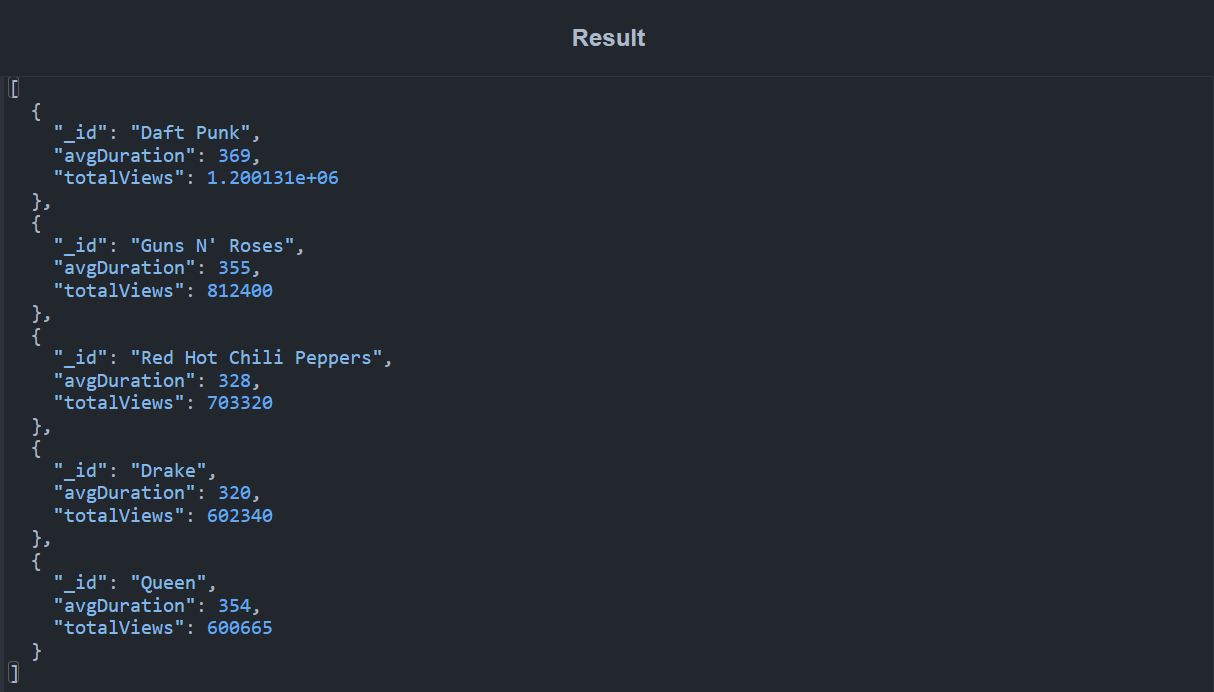
Continuing with this example, the streaming company also wants to know which genres have the fewest views.
The following query can be used to determine the top seven genres with the fewest views:
In this query, we use a $group stage to first identify all unique genres and then aggregate the number of views in the documents that correspond to each genre. Following that, we use a $sort stage to arrange the documents in increasing order of totalViews. Finally, we use the $limit stage to output only 7 documents. The output is displayed below:
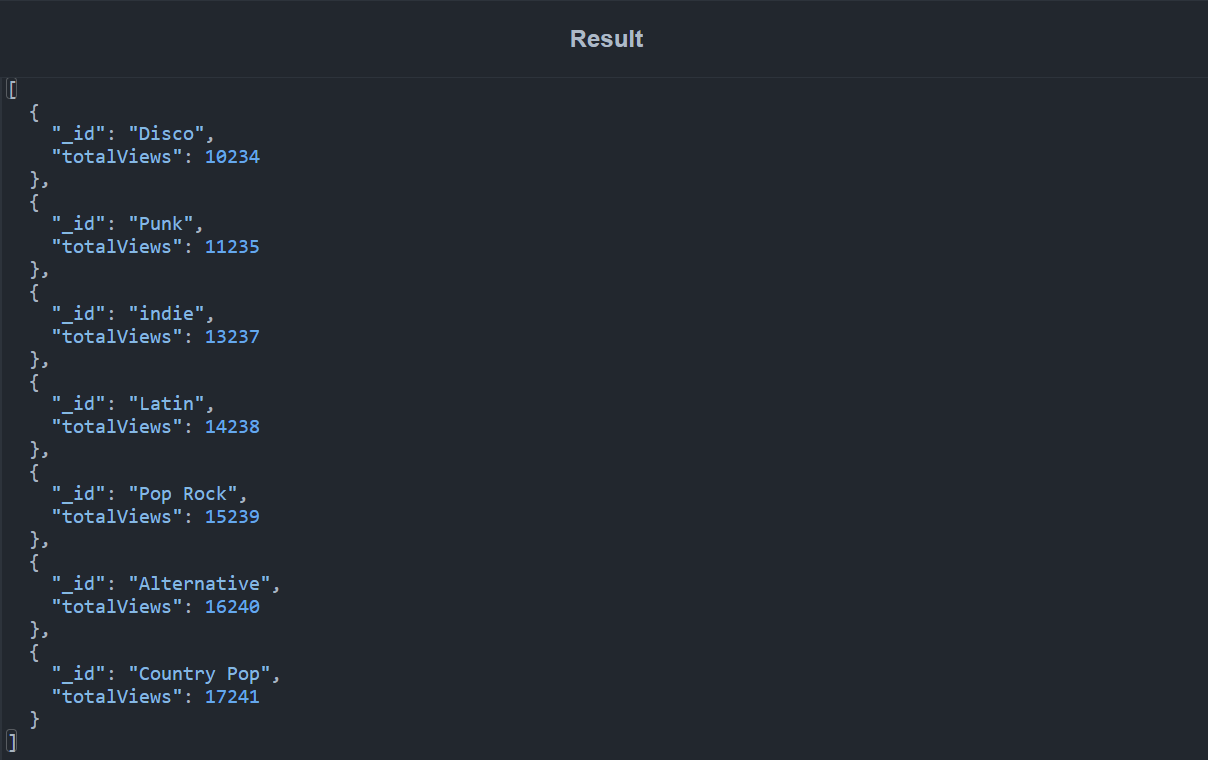
Other Use Cases of Aggregation Pipelines
Aside from streaming platforms, aggregation pipelines can also be valuable in other real-world scenarios.
Sales
MongoDB aggregation pipelines can be used to analyze large volumes of sales data and provide useful insights. If you need to better understand customers, you can build an aggregation pipeline to segment them based on various factors like buying behavior, demographics, or purchase history. This helps create personalized offers and targeted marketing campaigns.
Aggregation pipelines can also provide meaningful insights into sales trends and velocity by grouping and aggregating sales data based on various criteria, such as time period, sales channel, or product category. Additionally, they can be used to analyze data at various stages of the sales funnel to track customer interaction from initial contact to final purchase. This allows you to identify bottlenecks and improve sales efficiency and conversion rates.
User Activity
Aggregation pipelines can be used to analyze and process user activity data to gain a better understanding of how users interact with your platform. You can gain insight into user engagement patterns, for example, by grouping and aggregating user activity data based on various criteria, such as time period and activity type. You can also gain a better understanding of your users' behavior by tracking their login frequency, session duration, conversion events, and retention rates. This allows you to better understand them and devise strategies to increase customer retention. You can also aggregate and summarize users' social activity data with aggregation pipelines to gain insight into social engagement patterns, popular content, and user interactions.
Web Traffic
MongoDB aggregation pipelines can also help you understand your web traffic data. This could include page views, visits, and user interactions. You can create a pipeline to analyze this data and identify traffic patterns, popular pages, user engagement, and so on, by grouping and aggregating it based on criteria such as date, time, geographic location, and device type. You can also segment web traffic based on these criteria, which will inform marketing and content strategies. You can also use aggregation pipelines to compare the effectiveness of different versions of a website or a specific feature, allowing you to decide which works best and make effective data-driven decisions for website optimization.
Introducing Airplane: build powerful workflows and UIs efficiently
If you're looking to build a workflow or dashboard to manage your MongoDB database, then check out Airplane. Airplane is the developer platform for building internal tools. The basic building blocks of Airplane are Tasks, which are single or multi-step functions that anyone can use. You can also build Views, which are React-based custom UIs.
With Airplane, you can utilize pre-built components and templates to quickly build UIs and workflows. For example, you can build a database issues alert workflow, an admin panel, an AI database explorer, and more. Airplane also makes it easy to connect to resources, like MongoDB, easily.
To build your first workflow that connects to MongoDB easily, sign up for a free account or book a demo 👋
Author: Fortune Adekogbe
Fortune is a Python developer at Josplay with a knack for working with data and building intelligent systems. He is also a process engineer and technical writer.