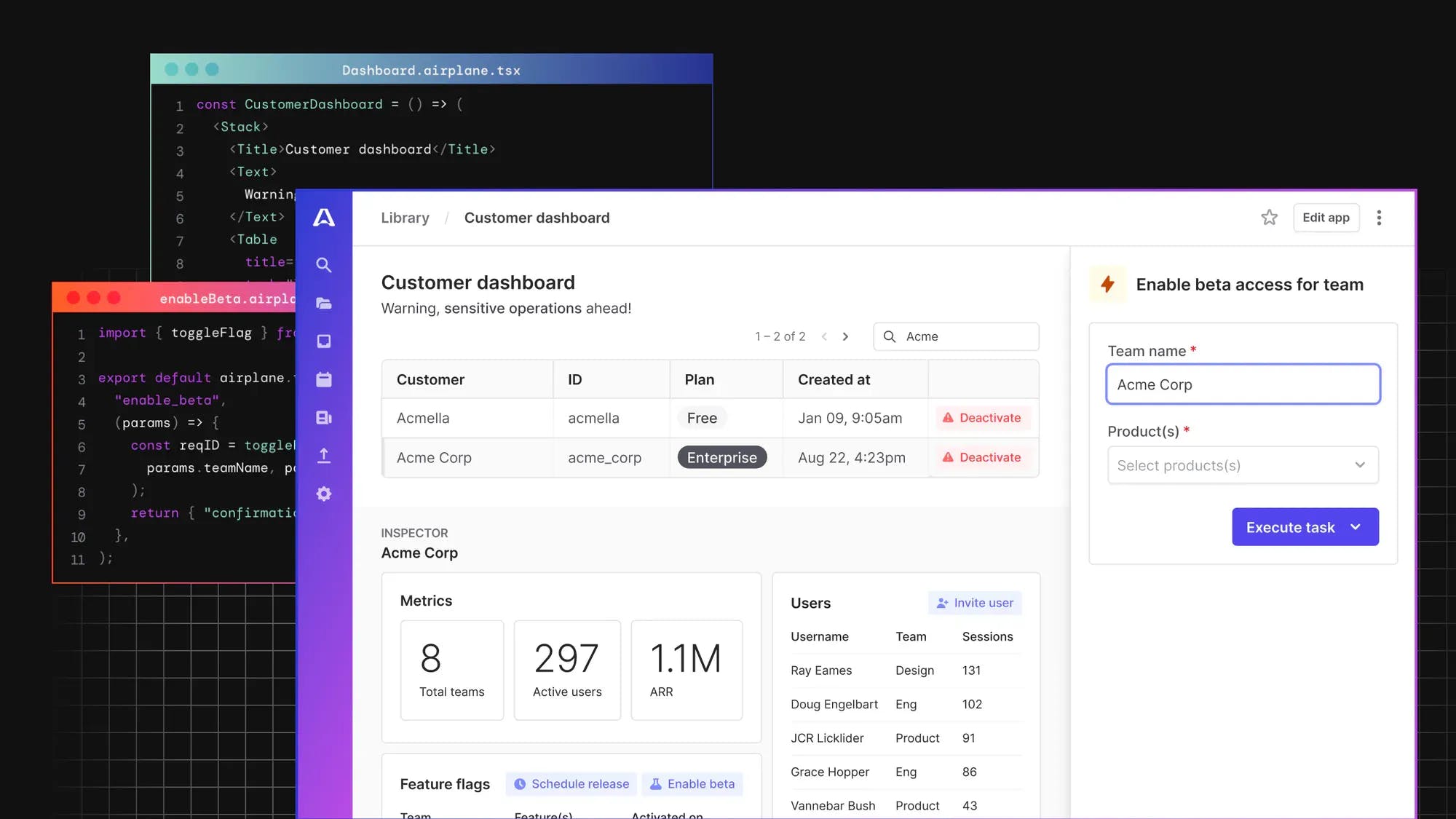
Virtually all Linux systems administrators are more than familiar with cron jobs. They’re exceptionally convenient tools for scheduling tasks to run automatically at specified times. However, when something doesn't work as it should, cron jobs can be difficult to debug.
Cron sends a job's output as an email to <user>@localhost, but only if we have an active SMTP server — and only if the job runs. When a job doesn't run, there are multiple possible causes. There might be issues with scheduling, permissions, or the executed job.
Debugging is never an exact science and these variables — both known and unknown — make it even more challenging. Without additional tools, such as those provided by a company like Airplane, we might spend a lot of time trying to locate the problem.
In this article, we’ll walk through some troubleshooting steps for determining the source of a cron job problem.
Locating the cron job
To debug a cron job, we first need to determine where we set up our job. There are multiple ways to do this. The first approach is to use the crontab (cron table) command, which is available for every user on the system.
You can view and modify your cron jobs using the command crontab -e. Every line returned represents one job and follows the format <SCHEDULE> <COMMAND>.
Here’s an example of what a crontab may look like:
Each command runs according to the given schedule and with the permissions of the user to which the crontab belongs.
If you’re a system administrator with root access, you have a few other options to find cron jobs. The /etc/cron.d directory contains files that describe cron jobs. Each file can have multiple lines that specify a job in the format <SCHEDULE> <USER> <COMMAND>. You’ll likely notice the <USER> variable, which does not appear in the results generated by the crontab command. For example, this is a cron job file pre-installed on Ubuntu servers (e2scrub_all) that regularly checks for filesystem errors:
There are also several other directories in which cron jobs may appear. These include /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, and /etc/cron.monthly. Unlike those previously mentioned, these directories don't contain schedules. Their files are scripts that run according to the schedule specified by the directory name.
The /etc/crontab file controls the exact times the scripts run. It lists cron jobs in the same format as used by the files in /etc/cron.d, and will look similar to this:
This file contains a job for each /etc/cron.* directory. Of course, you can also add your jobs to this file, but it’s likely more efficient to add a new file to /etc/cron.d instead.
As we’ve seen, there are several places in which cron jobs can exist. When debugging a cron job whose location is unknown, it’s important to remember that it can be in any of these places. Of course, context can help narrow your search. If a system user without root permissions sets up a cron job, you don’t need to sift through the /etc/cron.* directories. Instead, check the user's crontab.
Validating the schedule
We now know how to locate a job, so we can check its schedule when it doesn’t run as expected.
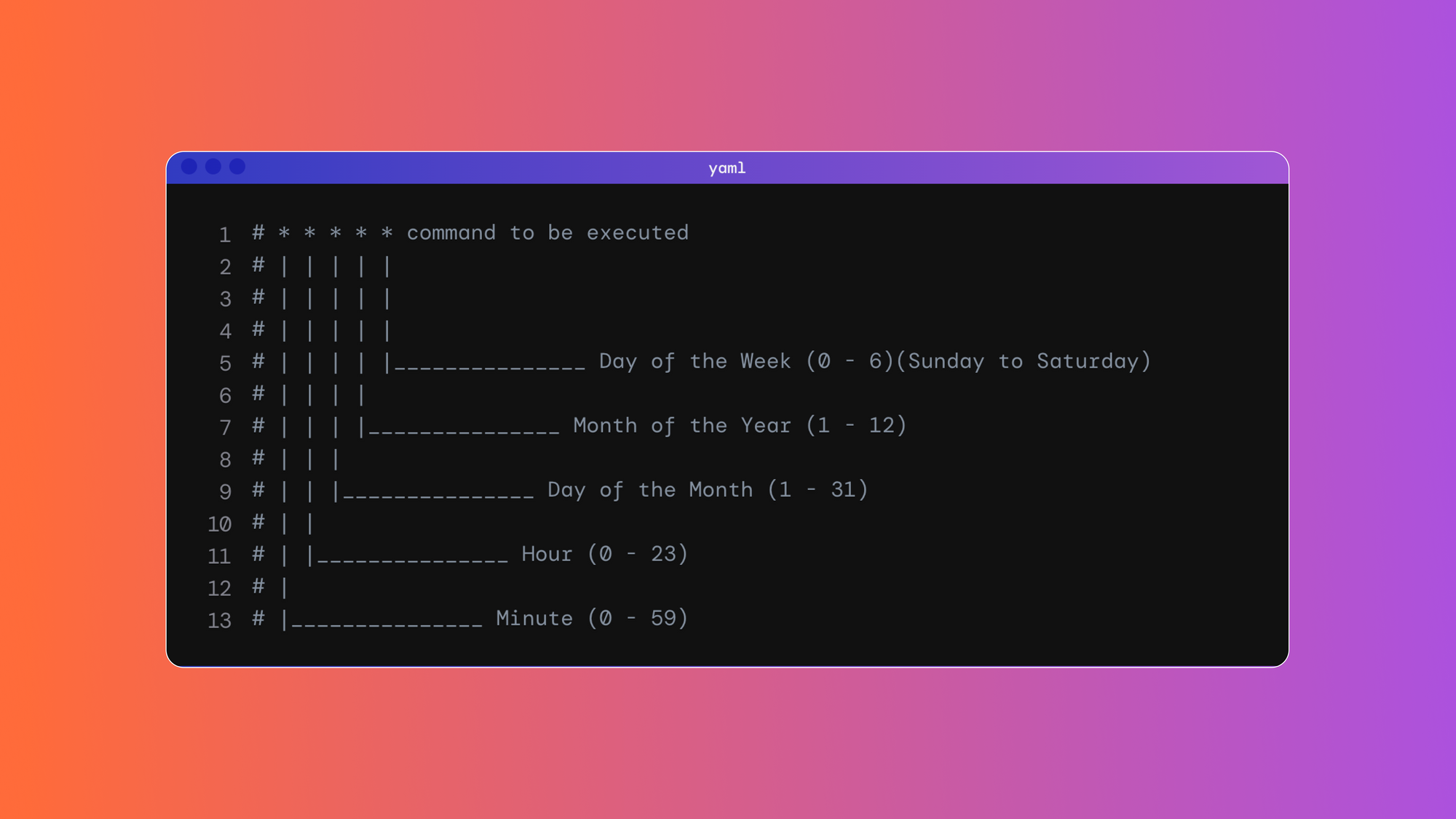
The schedule contains a combination of five elements: a number, a list of numbers, a range of numbers, or a wildcard (*). These elements can signify any of the following, which appear in this sequence: minute, hour, day of month, month, day of week. For the day of the week, the accepted range is 0 – 6, with 0 being Sunday and 6 being Saturday.
The following examples demonstrate how this schedule format works in practice:
7 * * * *means at the 7th minute of every hour7 1 * * *means at 01:07 every day7,14 1,2 * * *means at 01:07, 01:14, 02:07, and 02:14 every day7-10 1 * * *means at 01:07, 01:08, 01:09 and 01:10 every day0 3 1 * *means at 03:00 on the first day of every month0 3 1 1 *means at 03:00 on the 1st of January0 3 * * 2means at 03:00 every Tuesday0 3 1 * 2means at 03:00 on the first of every month and every Tuesday. It doesn't matter if the first of the month isn’t a Tuesday. Specifying both the day of month and day of week means the job executes on all of those dates.
If your cron job doesn’t run when you expect it to, you can review its schedule to see whether it matches your expectations. Cron follows the schedule in the server's time zone, which you can check using the date command.
Check permissions
To correctly run a command, the user must have permission to execute the command. For example, suppose that there’s a user named test and the following line appears in the user’s crontab:
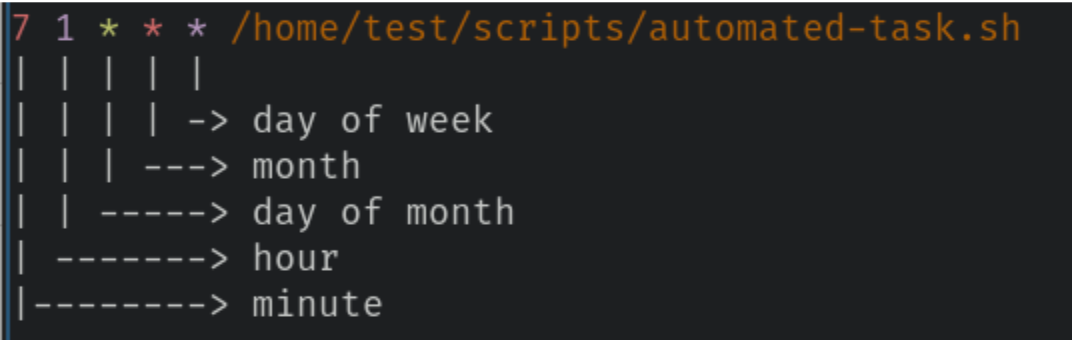
7 1 * * * /home/test/scripts/automated-task.sh
This runs the automated-task.sh script every night at 01:07. Below is the sample output of ls -l /home/test/scripts/automated-task.sh, a command that provides detailed information about the file:
-rw-r--r-- 1 test test 5131 Feb 16 23:33 /home/test/scripts/automated-task.sh

The first character of this output indicates the file type, using a hyphen to represent a normal file. The nine subsequent characters are the permission flags relevant to this section. The number after that indicates the number of links to the file. The next two elements indicate that the test user and the test group own this file. Finally, the line shows the date and time of the last modification and the file path.
You can separate the nine permission flags into three categories: user (owner), group, and other — each with flags specifying read (r), write (w), and execute (x) permissions. A hyphen indicates the absence of the permission.
For our example file, the owner (test) has permission to read and write to the file but not to execute it. Other users can read the file, but cannot write to it or execute it. Because the owner can’t execute the file, the cron job will fail. However, the file owner or the superuser can change this by setting the execute flag with the following command:
chmod u+x /home/test/scripts/automated-task.sh
The u+x command grants the execute permission to the file owner. Using ls -l again, we can see the execute flag:
-rwxr--r--

Initially preventing the file execution protects the file owner from doing so unintentionally. Allowing the owner to change this permission enables them to execute when needed and with the awareness that they are doing so.
Check the syslog
The syslog records executions of cron jobs. This enables us to check which cron job commands execute and when they do so. However, it should be noted that the syslog doesn’t log any output from cron jobs.
You can filter the syslog for cron job executions using the following command:
grep CRON /var/log/syslog
Each logged line follows the following format:
<date> <time> <hostname> CRON[<process id>]: (<user>) CMD (<command>)

If you're unsure whether your command was successful, you can check the syslog for pointers. The syslog rotates periodically. If its oldest entries are too recent, you can check older logs in /var/log/syslog.1.
Furthermore, you can locate even older entries in the compressed files /var/log/syslog.2.gz, substituting higher numbers for older files. For compressed files, ensure that you use zgrep instead of grep.
Check for overlapping jobs
Sometimes, overlapping jobs can cause errors. Two tasks might simultaneously access the same resource — a database, for example — and perform potentially conflicting actions. This can cause either job to fail, even if it worked properly when tested in isolation.
If you find such overlapping jobs, you may need to separate them within the schedule. Or, if overlapping is unavoidable in the specified period, you might need to coordinate the job functions accordingly. Of course, this requires additional programming effort.
Manually test the job
Every cron job specifies one or more commands to execute. You can manually run each command outside of the cron job and determine whether it functions properly. This enables you to determine whether there’s an issue isolated to the specific command, rather than one related to the cron job.
Conclusion
A lack of comprehensive error information can make cron job errors challenging to troubleshoot. Sifting through the various potential causes further complicates the debugging process.
Therefore, one of the most helpful tools in our arsenal is a standardized procedure for troubleshooting. This includes locating the job, validating its schedule and permissions, checking for jobs that compete over resources, and manually testing individual commands to isolate issues. Following these steps proves an effective approach for more accurate and efficient troubleshooting.
Debugging a cron job is time-consuming. Failures can happen silently if you haven't spent time adding logging or monitoring logic. Airplane is a serverless, managed alternative to cron that greatly simplifies troubleshooting, maintenance, and visibility for scheduled tasks. You can check out the Airplane blog for things like using Airplane schedules as a substitute for cron and how to start, stop, and restart cron jobs.
Airplane provides developers with an easy way to schedule jobs efficiently and effectively. In addition to Task scheduling, Airplane has a feature called Views, which allows users to rapidly build custom UIs, and a feature called Workflows, which allows developers to orchestrate powerful multi-step operations as code.
If you'd like to try it out you can sign up for a free account or say hello at [email protected]!