Modern software systems are complex and can exhibit emergent behaviors ranging from performance slowdowns, to partial failures, to full outages. When these happen, it’s important that (1) the right people are alerted, (2) there’s a centralized place for discussing the incident and its resolution, and (3) a “post-mortem” is done to ensure the incident’s root cause(s) are understood and mitigated.
Based on our experiences at our former employers, including Stripe, Segment, and Airbnb, we’ve developed a lightweight but effective process at Airplane for addressing the previous requirements. This process only depends on Slack (which our team, like many others, already uses for day-to-day communication) plus a small amount of coordination code, which we've posted in the airplanedev/blog-examples repo.
In the remainder of this post, we describe how our process works and how we implemented the associated tooling.
How it works
(1) Creating an incident
If any member of the team sees something that might be an incident, they can go to any channel in Slack and type /incident.
This message is routed to our incident manager app (described more later), which gives the reporter a form to fill out:
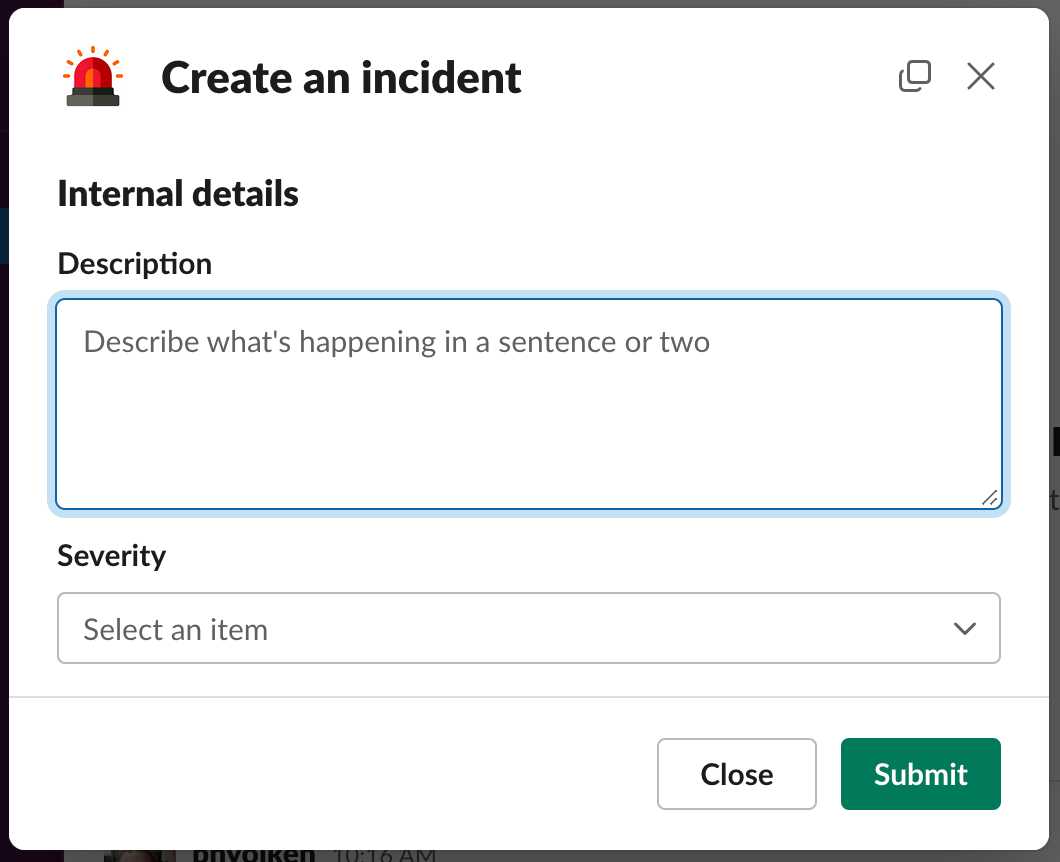
Once the reporter hits “Submit”, the incident app does a few things:
- Create a name for the incident. By convention, we use the format
YYYYMMDD-adjective-animal, e.g.20230601-honest-rhinoceros, where the adjective and the animal are picked at random from pre-defined lists. - Create an incident-specific Slack channel, e.g.
incd-20230601-honest-rhinoceros. This is where members of the team can discuss the incident and its mitigation, as described more below. - Create a PagerDuty incident to alert the primary on-call engineer
- Post messages in a few company-wide channels to let others who are not on-call know about the incident
- Create a skeleton document that will be used for the post-mortem (discussed more below)
(2) Responding to the incident
The on-call engineer, the incident reporter, and anyone else who has context on the problem meet in the incident-specific Slack channel. Here, they discuss what’s happening and how to fix whatever is causing problems. This is also where it’s decided whether and how to notify customers (we use Atlassian's Statuspage product for general external alerts, and we can also email or Slack customers directly).
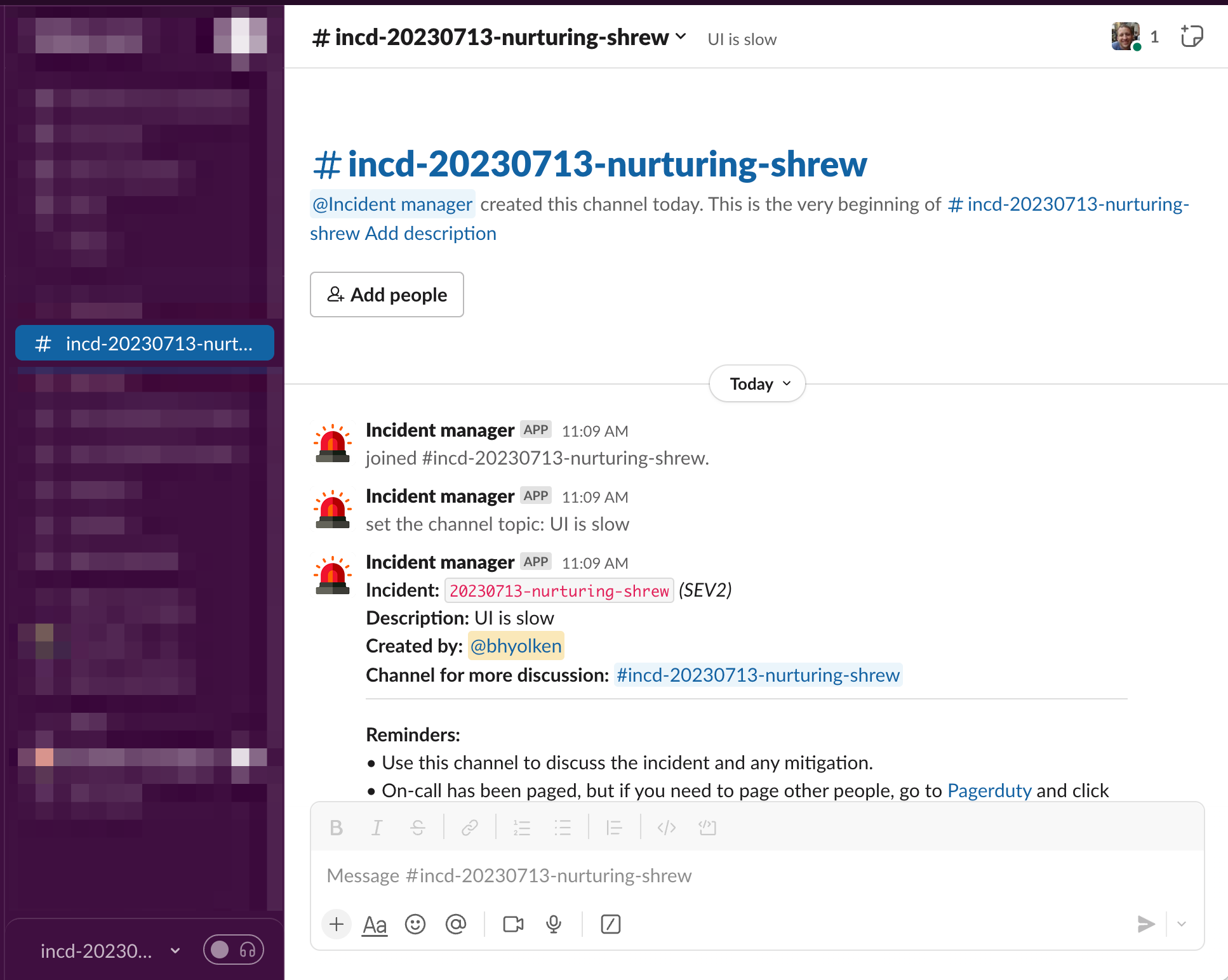
The Slack channel not only allows the team to coordinate in real-time, but also serves as a long-lived record of what happened when. This is helpful for filling out the post-mortem doc and also searching back over prior incidents when something similar happens later.
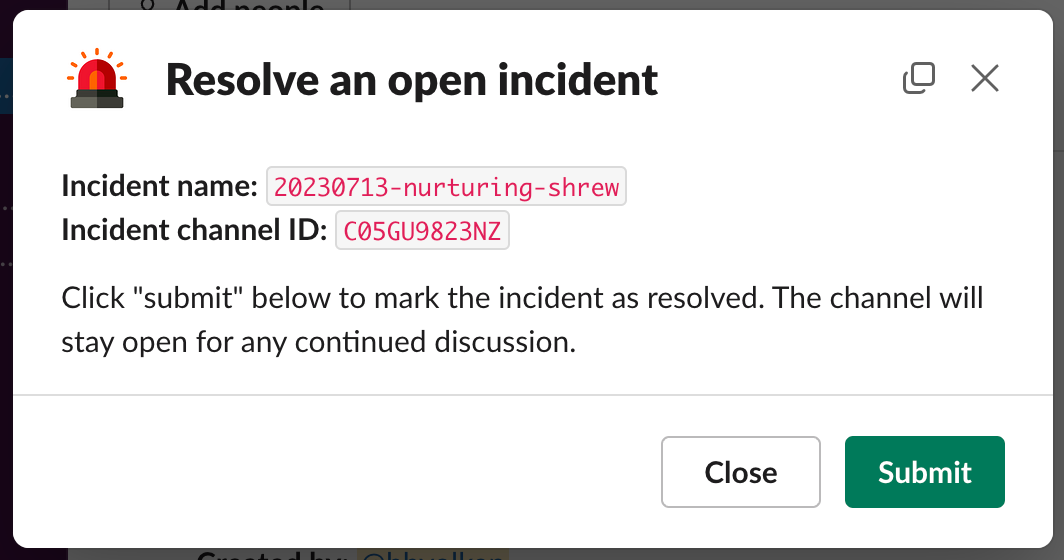
(3) Marking the incident as resolved
Eventually, the team figures out what’s going on and fixes the underlying problem (hopefully!). At this point, the incident is marked as resolved by someone typing /resolve-incident in the incident Slack channel. The incident app then:
- Appends
-resolvedto the Slack channel name (but keeps the channel open so discussions can continue as needed) - Posts “incident resolved” messages to the company-wide channels that were alerted when the incident was created
(4) Performing a post-mortem
Once the incident has been resolved, a member of the team is designated to fill out a post-mortem doc in Notion. This is typically the person with the most context on what happened, either because they were actively involved in the response or because they worked on the change or system that caused the incident to occur.
A skeleton post-mortem doc is created automatically by the incident manager app when the incident is reported. It includes the following sections:
- Incident description and Slack channel link
- Incident timeline
- Root cause analysis
- Mitigation tasks for the engineering team
Once these are filled out, the post-mortem writer schedules a 30 minute meeting with everyone on the engineering team invited (but optional unless they were directly involved).
At the meeting, the writer reviews the document and leads a discussion of the root cause and follow-up mitigation tasks with those present. The company’s CTO and/or head of engineering, who attend all incident meetings, help ensure that owners are assigned and existing work is reprioritized as needed to address any high-priority follow-ups.
At the conclusion of the meeting, the incident is formally closed and the associated channel is archived in Slack. The document and the channel serve as records that the team can refer back to in the future if similar problems occur.
App code
The incident manager app described above was implemented as a small JavaScript service using the Slack Bolt SDK. The nice thing about this approach is that it requires minimal code and also doesn’t need any publicly accessible network ingress- instead, Bolt initiates outbound connections to the Slack API and receives requests via websockets.
A simplified version of our code is available in the airplanedev/blog-examples repo. As noted in the README there, this code should be considered a starting point as opposed to a drop-in-place solution. Based on your organization’s procedures and requirements, you’ll probably want to edit the messages, swap out dependencies, and/or add in extra API calls. Another possible enhancement is to store the details of each incident in a database; we don’t need this yet because of our small company size (just having records in Slack and Notion is enough), but it might be helpful for a larger organization.
What about using an external vendor?
Several companies offer “incident response as a service” products. We evaluated these before writing our own app but concluded that they were overkill for our needs. If you’re at a larger company and/or have highly complex incidents, they’re worth exploring. But, if all you need is a discussion channel plus some external API calls (for paging the on-call, creating an incident document, etc.), then the build-it-yourself solution may be sufficient.
Conclusion
The process and tooling described above have significantly improved how we handle incidents at Airplane. What used to be an ad-hoc process with discussions spread across multiple places (including 1:1 chats) is now fully structured, centralized, and visible to all members of the team. Incidents still happen and can still be stressful for both us and our users, but we’re now more confident that they’ll be resolved quickly and that mitigations to prevent future problems will be rigorously identified and prioritized.