


I often get questions from founders about how they should think about the “technical moat” of what they’re building, or from potential employees about our technical moat at Heap. If you have a successful product, what’s to stop someone else from building it?
Technical moats exist, but they rarely take the form people expect them to take.
People often look for an answer to that question in the form of a monolithic, singular technology, like a single algorithm, or a particular piece of code nobody else can replicate, or a branded Whiz-Bang Platform. But, more often, technical moats take the form of many, many incremental improvements to one basic idea.
In the long-term, all technology becomes commoditized. All tech moats are temporary, because the tide of technology is always rising. So the question becomes: what is hard to replicate in the short and medium term?
This is especially true for software companies in 2021, with such an enormous open source ecosystem to build on. You probably aren’t building a unique new machine learning algorithm or a shiny new datastore, because in all likelihood you don’t have to. [1]
What’s the hardest part of building the world’s fastest database?
Consider SingleStore, formerly known as MemSQL. They’re a database company, so you would imagine their technical moat is core to their ability to sell at a high margin.
They have a lot of fantastic blog content about the algorithmic work they've done to make their product blazing fast. (E.g., lockfree skiplist indexing! Extremely cool!) One might imagine that this is their "moat".
But if you ask their early team about what made their product hard to build and would make it hard to replicate, the answer is much more mundane: their product is drop-in compatible with MySQL, which means buyers can start using it without a massive effort to port a system that’s been running on MySQL to being compatible with something new.
Delivering that drop-in compatibility requires getting an enormous number of annoying, boring details right, to exactly match MySQL's notoriously bizarre semantics. All the MySQL defaults, prefs, flags and so forth – it all has to Just Work when you use SingleStore instead.
The fancy data structures get attention and provide credibility to a technical buyer, but the real moat comes from reimplementing MySQL’s bugs.
SingleStore also needs a world class query engine. When they get their foot in the door with a legacy system, the product needs to deliver huge performance improvements. But sometimes the “moat” comes from non-obvious places too, and this is one example.
What is Heap’s moat?
Heap is a product analytics company built around automatic data capture, or “autocapture”. Instead of requiring customers to write tracking code for each behavior they want to analyze, Heap captures everything, automatically. That means our customers always have the data they need to answer questions, instead of having to get new code shipped and wait for data. This approach also lets Heap proactively flag interesting or unexpected phenomena in user behavior, since it’s built on a complete dataset.
People often point to autocapture as Heap’s technical moat, which is on the right track, but it’s not quite right. The technical pieces of our product that would be the most difficult to replicate are 1) the data infrastructure we've built to make an autocapture product scale to big datasets and stay cost-effective at scale, and 2) the details of the data capture, including the complete product to make this dataset useful.
Note that both of these are the results of iteration and incremental improvement, not a single monolithic technology or capability.
It's not hard to make a piece of code that captures most clicks on a website, and in fact you could do it as a hackathon project. But building an autocapture product and making it actually useful requires a lot more:
- Dozens of details to make the autocapture dataset complete enough to answer 95% of the questions a user would have, instead of 70%.
- Making your autocapture reliable in all the different environments a reasonable user will expect it to work, e.g. across different browsers and OSes.
- Keeping your autocapture code from breaking all the various different ways people make websites, e.g. SVGs or strange form semantics.
- The ability to make autocaptured events semantically useful, i.e. the ability to "define" events in human-meaningful terms and query them in realtime.
- The ability to keep a virtual dataset organized, since you’ll be enabling 100x as many people to participate in creating it.
So I would also consider, for example, a feature that lets you bulk delete event definitions that are defined on top of the autocaptured dataset to also fall into this category and be part of Heap’s true technical moat, even though you wouldn’t ordinarily think of that as a “technical moat” because it’s mundane and, on its own, is easy to replicate.
You might not think of a bundle of features like a better UX for dataset cleanup, verification flows, proactive alerting when events break, and so on as part of “the technical moat of autocapture”, but I think you should. Each of these is replicable, but in aggregate they take a lot of time and iteration to get right. That time and iteration is the moat. [2]
Notice that a lot of these details are not obvious upfront. That’s another part of the head start that usually accompanies a technical moat: a more intimate understanding of the problem. It’s not clear upfront, for example, that supporting SVGs or making it easier to govern an autocapture dataset at scale are extensions of this problem, and a follower will need to learn it for themselves.
Over the past two years, we also developed Illuminate, a suite of data science features that proactively flag important phenomena from the autocapture dataset. It extends our moat in the same way. There’s no new machine learning algorithm that nobody else has access to. Rather, what makes Illuminate so useful are the dozens of rounds of iteration and tweaking and revision that we invested and continue to invest, to get the details of these features right.
Heap’s data infrastructure moat
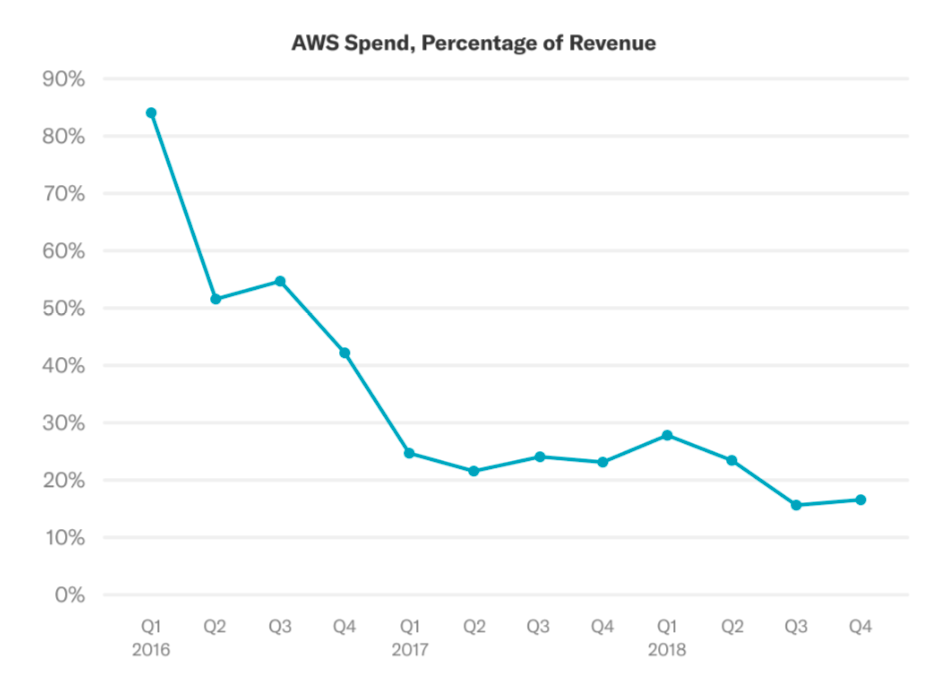
Another aspect of Heap’s moat is its data infrastructure. In the early days of Heap, we shipped an initial product that didn’t scale well to large websites, and which cost so much to deliver that our unit economics didn’t make sense for a SaaS business. This is ok – these are both problems we had conviction we could solve with more investment. Sometimes the purpose of your early stage product is to get validation that it even makes sense to invest further.
Once we had that market validation, we set out on a multi-year process to make our data infrastructure scale cost-effectively. We started from a product that cost almost 100% of our revenue to deliver and iterated our way to a product that cost below 20% a few years ago – a more typical SaaS margin – and even lower since then.
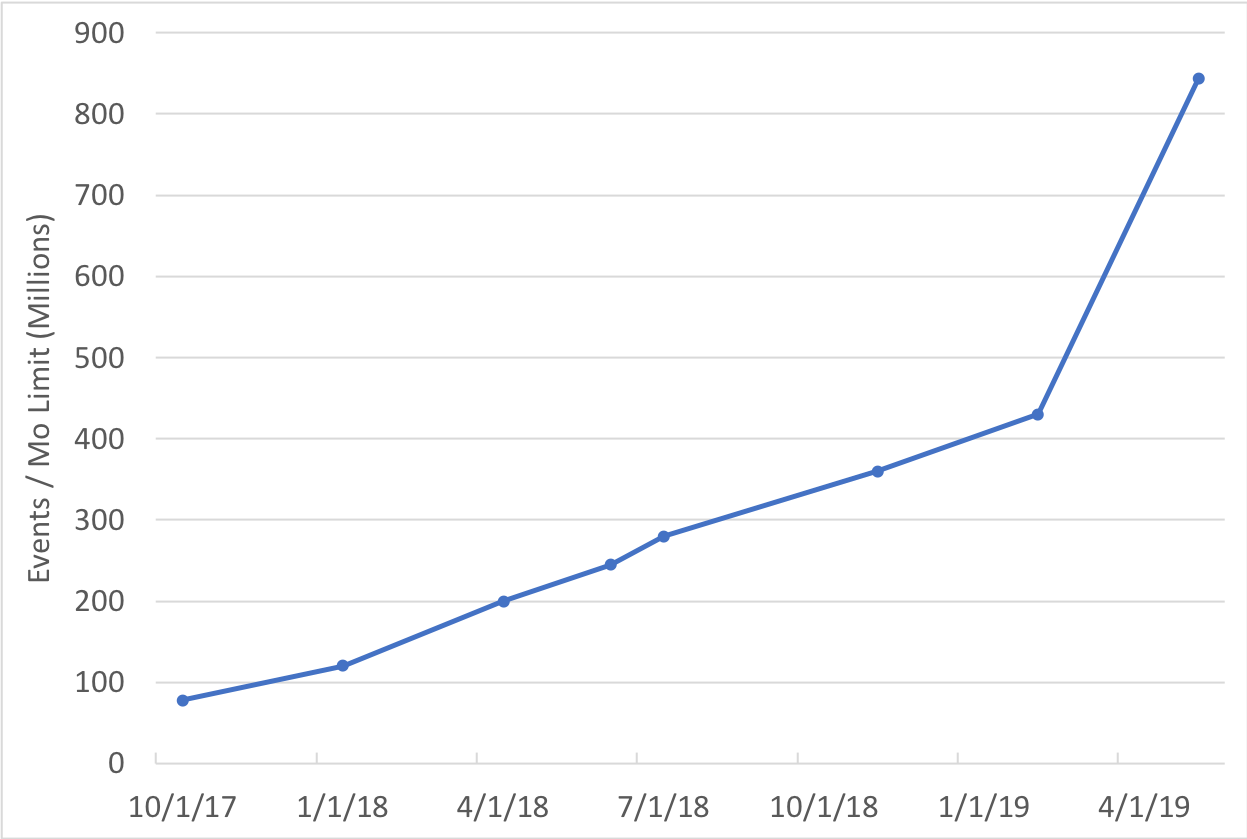
Here's another example: this graph shows the size of customer we could safely support, at different points in time from 2017 to 2019. This took years of iteration to get to the point where we could serve customers doing hundreds of millions of events per month. (And, likewise, there’s always more work to be done on this front.)
These "technical moats" didn’t come from one singular, monolithic technical breakthrough. It’s not like there’s a piece of code in our product that nobody else could write. Software moats don’t work that way.
Rather, the moat comes from many smart iterations, in a focused direction, rooted in a fundamental user need. Autocapture works this way, data governance works the same way, and the proactive insights features we’re developing now will definitely work the same way.
Consequences
One important consequence is that technical moats aren't "finished". If you don't keep investing in them, they erode relative to the rising tide of technology. Over time, it will get easier and easier to replicate your work.
This also means you shouldn’t expect an early stage startup to have a technical moat, because there hasn’t been that much time to build. There are exceptions, e.g. if a company is commercializing technology that’s been developed elsewhere, but in most cases a company at this stage won’t have much of a technical moat at all.
That’s ok. The right thing to look for at this stage is problem depth. If the problem you’re working on solving is deep and there are many, many ways to make your offering more valuable to customers over time, you’ll accrue a moat over time. If you execute well, by the time you’re successful enough to have something worth replicating, you’ll have accumulated something that will take time for anyone else to replicate.
Problem depth also means you’ll accrue problem intimacy over time, which will take your competitors years to learn. When a competitor tried to replicate autocapture, they didn’t realize that not capturing end users’ passwords is an important part of the problem and can be trickier than it seems. This was something we had figured out five years prior, when we had first started working on the problem. The lack of problem intimacy led to major reputational damage and, ultimately, the failure of their new product line.
On the other hand, if you’re attacking another company’s technical moat, you should beware the hubris that comes from ignorance. A key feature or technology might seem like it will only take two months to replicate, but you might not see the six months of additional features that fill out the offering. If those details matter, the customer will know the difference, and you’ll be left with an incomplete feature in need of a lot more investment before it’s competitive. [3]
Another consequence of this model is that you can only “defend” a moat by investing more in it. As a startup, you have basically no recourse to keep someone else from replicating the work you’ve done so far. The complexity of the moat buys you time while they work out the details. All you can do is make your own product more valuable in the meantime.
That's part of why it's so key to continue investing in the fundamental capabilities that drive your differentiation, and especially to keep finding ways to make them more valuable. Taking Heap as an example, autocapture is a deep problem, and nine years in we're finding new ways to do it better.
For example, we have a Snapshots feature that lets users enrich their Heap dataset with additional page content. We shipped what might seem like some incremental improvements to this feature in mid-2020, which let users more easily create Snapshots based on form field contents. This increased the number of Snapshots our customers created, by a factor of 10! This is an incremental improvement to a feature that is itself a secondary feature that extends our core autocapture approach, but it all adds up to extending the same moat and making it more difficult for another product to deliver a comparably valuable experience, along the underlying axis our users care about: ease of creating a useful dataset.
As another example, we just launched our data engine last July, which I think is also an extension of our "autocapture moat", and is itself the first of what will be many iterations before we've really built out the tech that makes it easy to govern a Heap dataset at scale.
Moats start from the customer
Another consequence is that your moat has to be anchored to customer value. The fact that a piece of technology is hard to replicate on its own doesn’t protect your company from competitors. That technology is only a moat if it delivers something your customers care about and will pay a premium for. Otherwise it’s more like a pond near your castle: lovely to skip rocks in, but it doesn’t give you any protection.
Jeff Bezos’ thought experiment – what isn’t going to change in the next 10 years? – is brilliant in this regard: if you ask yourself what customers will always want more of, and focus your effort on better ways to better deliver it, you’ll accrue something very valuable and hard to replicate, i.e. a moat.
That also means your reaction to competition has to start from ways to make your product more valuable to the customer. If there are ways you can further invest in your current moat that will be extremely valuable to your customers, then those investments might be your best plan. But if you don’t have good ideas for making your current moat solve problems your customers care about, piling on more investment won’t keep competitors from replicating the subset of it that your customers do care about. That means sometimes the right course of action is to let competitors replicate what makes up your current moat.
So, in a long-term sense, your moat comes from:
- More intimate understanding of your customer.
- Faster product iteration.
- Focus, on a consistent problem.
These are the forces that create valuable technology that’s hard to replicate. The rest is mostly branding.
This is a guest post from Dan Robinson, CTO of Heap. Over the last 8 years, Dan has helped scale Heap’s analytics infrastructure to support thousands of customers and trillions of data points. Follow Dan on Twitter: @danlovesproofs
[1] And, doing so when you don’t need to is no moat at all, unless you can use it to provide a superior product to your customers. If not, your competitor can still use the excellent off-the-shelf technology you didn’t use. And the off-the-shelf technology is getting better all the time, at no cost to them, whereas your in-house system only gets better when you invest in it.
[2] A related and important concept is "process power", which are differences in how a company executes that are very hard to replicate. (Think: how Toyota beat GM, or why it's so hard for nontechnical institutions to replicate "technical innovation" that startups do naturally.) There's a great description here.
[3] Note the assumption here that the quality and completeness of your product matter. The customer isn’t always the user, and your product needs to be differentiated in a way that will be visible to the person making a purchasing decision.


