


As a microservices developer and architect, you’re asked to problem-solve a few specific pain points:
- How can you deliver observability by collecting metrics and telemetry from your services?
- How can you use mTLS to create secure lines of communication between services?
- How can you improve reliability by using retries, timeouts, load balancing, and traffic shifting?
Instead of developing and maintaining solutions to tackle security, discoverability, or observability, you can leverage a service mesh to offload those operational concerns. At a high level, a service mesh helps reduce the complexity of microservice deployments and lets development teams concentrate more on the application logic.
In this article, you’ll learn what a service mesh is, its main features, and what to consider when you want to use one. You’ll also learn about some popular service mesh implementations, see where service meshes may not be a good idea, and learn how to deploy a Kubernetes-based service mesh.
Why service meshes are important
A microservice architecture defines a structure where services are loosely coupled and work together to achieve an overall application function. This ensures easy maintenance, modular testing, faster delivery, deployment independence, and ownership by smaller teams. But it doesn’t come without its challenges.
Managing reliable network connectivity in distributed systems takes careful planning, and microservice architecture introduces a new set of challenges:
- Service Discovery: Since application functions are split into different services, they need a way to find each other and communicate to make calls.
- Load Balancing: each service can scale independently and needs load balancing between its different instances.
- Fault Tolerance: One service failure shouldn’t halt the entire business, so there should be built-in resiliency measures in place.
- Distributed Tracing: You need to understand how services are interacting, how long they’re taking to perform certain tasks, and if an error happens—where that error is generating.
- Metrics: Each service needs to export metrics consistently, and you need the ability to relate them to each other to get the overall application performance.
- Security: You need to employ authentication, access control, and encryption to ensure security.
Each service needs to address and implement these features independently. And they need to do it no matter the programming language or framework they’re built on.
To achieve this, you can create libraries and implement them within the service code. But that means you also have to develop, evolve, and maintain those libraries for each technology stack, and ensure all development teams are using the correct version.
A service mesh takes away this whole complex part by using a proxy. Services can focus on running business logic and allow the service mesh to handle things like service discovery, routing, or tracing.
How service meshes work
Most service mesh implementations consist of two main components: the control plane and the data plane.
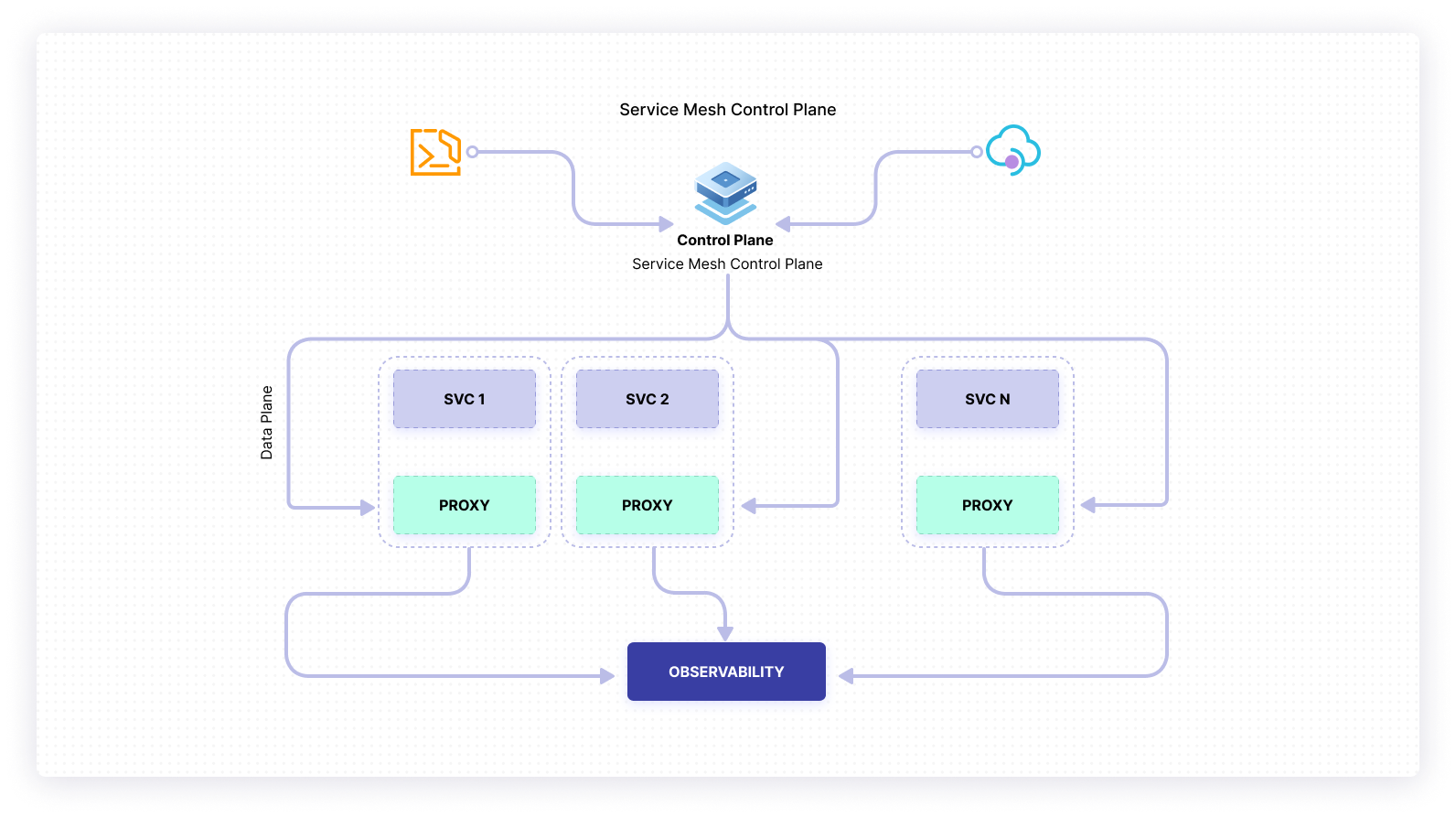
The control plane consists of a set of services that provide administrative functions over the service mesh. You will interact with the control plane by using a CLI or an API to configure the service mesh. For example, as an administrator, you will define routing rules, circuit breaking rules, configure observability, or enforce access control.
The data plane composes your services along with their proxies, called sidecars.
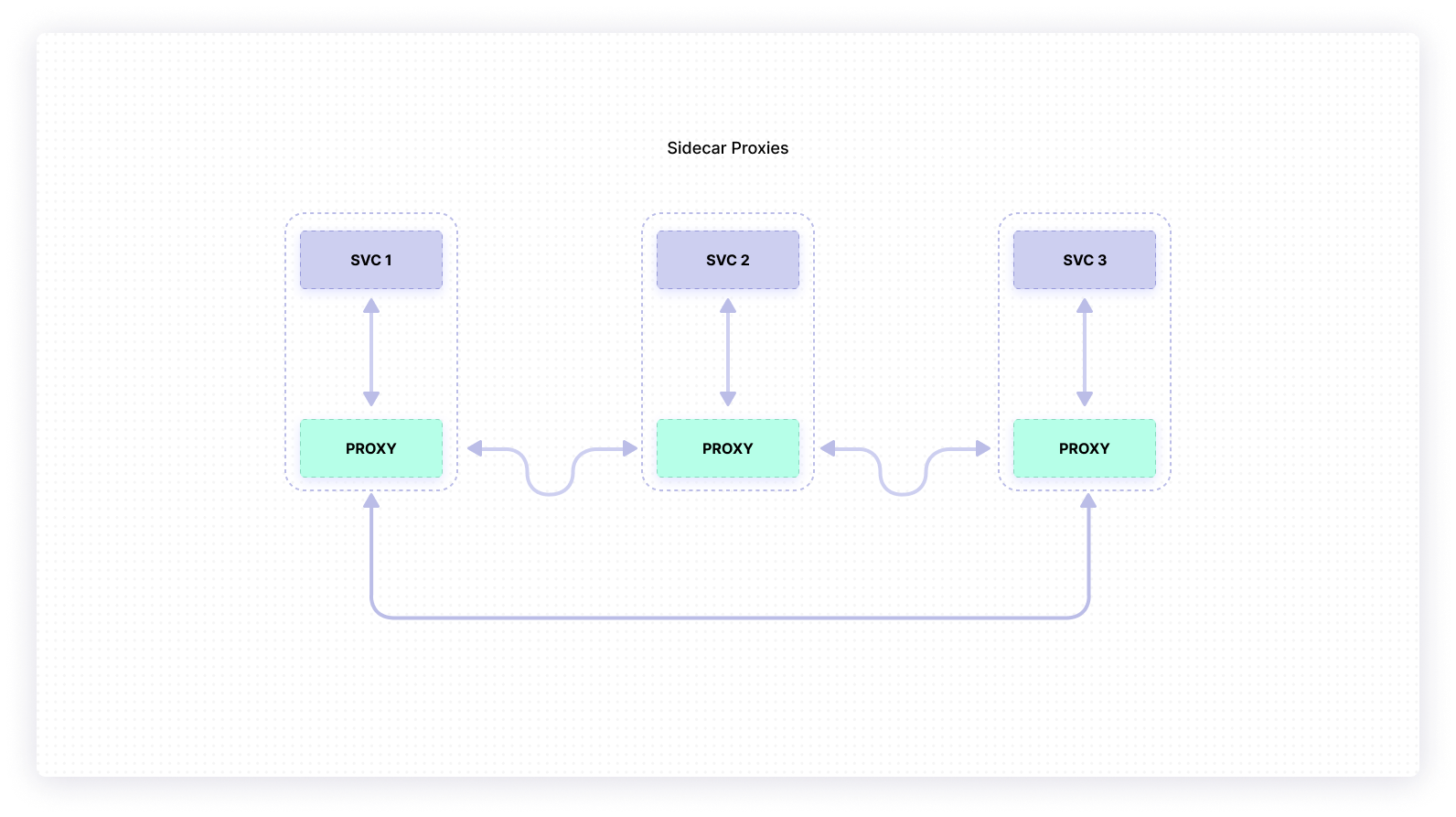
Those proxies will sit alongside the services themselves. All traffic will flow through them (both ingress and egress) and they will be responsible for routing (or proxying) traffic to other services. Together, they will create a mesh network, a type of network topology where services can connect directly and dynamically with no need for particular nodes to perform specialized tasks. These proxies will get their configurations from the control plane and can export metrics, traces, and logs directly to another service or through the control plane.
Many of the features you’ll need function at the request level and, as such, the sidecars will be Layer 7 proxies. This will allow them, for example, to load balance intelligently based on observed latency or retry requests upon failure. Also, the sidecars add functionality at the connection level. For example, sidecars can implement TLS connections, allowing both sides of the connection channel to validate the others’ TLS certificate before communicating.
Some popular service meshes
There are several service mesh products in the market today, the most popular ones being Istio, Linkerd, and Consul. At their core, they follow a similar architecture (and a general set of functionalities) to the one we showed before, but each comes with some extra features, with varying degrees of complexity.
Istio comes with a rich feature set. Born out of the partnership between Google, IBM and the Envoy team at Lyft, it delivers features—like service-to-service communication with TLS encryption, authentication and authorization, automatic load balancing, fine-grained routing rules, retries, failovers, and fault injection—as well as observability capabilities with metrics, logs, and traces for both ingress and egress traffic. Its control plane, istiod, provides service discovery, configuration, and certificate management. Istio leverages Envoy as its proxy sidecar, and istiod is responsible for converting high-level rules into Envoy-specific configuration.
Linkerd was the first popular service mesh implementation. Linkerd focuses on simplicity and performance, and builds on top of Kubernetes. It delivers a slightly smaller feature set when compared to Istio, while maintaining a good balance between complexity and features. Linkerd offers its own proxy implementation: linkerd2-proxy is written in Rust and focuses on being simple and ultralight.
Consul started as a service discovery solution. Built by HashiCorp, Consul Connect provides service-to-service connection authorization and encryption, and uses Envoy for its sidecar proxy. It also has a well-defined API that allows other proxies to integrate easily with Consul. Unlike Linkerd, which only targets Kubernetes environments, it can be used in a variety of platforms.
Each of these service meshes has their own vibrant open-source communities, as well as commercial support. Linkerd and Consul have commercial support from their original creators and main contributors, with Buoyant for Linkerd and HashiCorp for Consul.
The cases against service meshes
Despite the benefits, service meshes have some caveats.
For starters, it’s another piece of software to manage, configure, and maintain. Also, consider the following:
- Complexity: Service meshes add new components to your overall solution architecture. Irrespective of what service mesh product you choose, you’ll always have to manage an extra set of services (control plane services) and configure each sidecar proxy.
- Resource consumption: The sidecar proxies use resources like memory and CPU, and that usage will scale with the number of services your application uses.
- Cost: Apart from the product’s price, the extra computing resources needed by the control plane and the sidecars will have a financial component.
- Extra network hops: Although sidecar proxies offer a lot of functionality, they add an extra network hop for a service when it communicates with another service.
- Debugging: Debugging distributed systems can be complex and adding extra services through a mesh can make the process even more complicated.
Setting up a service mesh
Deploying a service mesh is highly dependent on the product you choose. Istio, Linkerd, and Consul all offer excellent guides on how to get started, as well as production considerations and setup patterns available for use.
At a high level, a service mesh needs you to onboard two main components: the control plane and the data plane. The control plane will deploy a set of services that you’ll use to configure and maintain the mesh. In Kubernetes environments, you’ll usually deploy it using the service mesh’s respective CLI (e.g. istiod, linkerd, and Consul) or via Helm (e.g. istiod, linkerd, and Consul).
Although you can deploy sidecar proxies manually, automation is preferable. Cloud-native, Kubernetes-hosted workloads are usually large, complex, and elastic—meaning manual proxy deployments are susceptible to errors and misconfiguration. To address this, service mesh implementations offer solutions to automatically inject sidecar proxies. For example, Istio, linkerd, and Consul will configure themselves by connecting to the control plane and fetching necessary configuration.
Take Istio, for example, a deployment in Kubernetes with Helm and automatic sidecar injection can be done with the following steps:
Create a namespace for the control plane:
Install Istio’s cluster-wide resources:
Install istiod:
Enable automatic sidecar injection on specific namespaces. For every new pod, Istio will automatically inject the side proxy:
Final thoughts
A service mesh is a dedicated infrastructure layer that decouples some of the critical operational tasks of a distributed application from its business logic. Large-scale, Kubernetes-hosted microservice applications are natural candidates for service meshes due to their complex requirements of inter-services communication (e.g., retries, timeouts, traffic splitting), observability (e.g., metrics, logs, traces), and security features (e.g., authentication, authorization, encryption). Service meshes can offload many operational concerns of the Kubernetes cluster, leaving the developers to focus on business logic.
However, despite the benefits, service meshes come with their own challenges. As you saw, complexity, resource consumption, cost, extra network hops, and debugging are some of those concerns. You’ll have to take these into consideration when re-architecting your application to include a service mesh. Also, different vendors’ products have different sets of features and complexities. Some are simpler than others. Some, despite having fewer features, may have a lot less maintenance overhead.
If you're looking for a maintenance-free platform that makes it easy to build dashboards for monitoring your Kubernetes applications, then Airplane is a good solution for you. Airplane is the developer platform for building custom internal tools. Using Airplane Views, you can quickly build React-based dashboards that make it easy to monitor your applications in real time.
To build your first monitoring dashboard using Views, sign up for free or book a demo.


