


So you’ve encountered a CrashLoopBackOff error when running Kubernetes pods—worry not! Despite what some might have you believe, this is not the end-all of errors. With a little effort, it can lead you straight to the reason why your pod is crashing in a loop.
It’s comforting to treat CrashLoopBack as a status update more so than an error. Just as a pod can be either Pending just after it has been created, Running when active, and Successful when it has completed its scheduled runtime, the CrashLoopBackOff is also a state confirmation. Then there’s the Failed state, which by all manner of reasoning should be more alarming than a looping state.
Let’s explore what a CrashLoopBackOff error really means and how you can use kubectl commands to drill down and debug. By the end of the article, you’ll be able to troubleshoot and resolve the state from its point of origin.
What does CrashLoopBackOff mean?
CrashLoopBackOff is a status message that indicates one of your pods is in a constant state of flux—one or more containers are failing and restarting repeatedly. This typically happens because each pod inherits a default restartPolicy of Always upon creation.
Always-on implies each container that fails has to restart. However, a container can fail to start regardless of the active status of the rest in the pod. Examples of why a pod would fall into a CrashLoopBackOff state include:
- Errors when deploying Kubernetes
- Missing dependencies
- Changes caused by recent updates
Errors when deploying Kubernetes
A common cause for the pods in your cluster to show the CrushLoopBackOff message is due to deprecated Docker versions being sprung when you deploy Kubernetes. A quick -v check against your containerization tool, Docker, should reveal its version.
To fix this, and as a best practice, make sure the latest version of Docker and any other plugins within your workflow are at their highest, most stable versions. This way, no inconsistencies or deprecated commands trip containers into start-fail iterations.
If you’re migrating projects into your clusters, meeting incoming projects’ Docker versions can even mean rolling back a few versions.
Missing dependencies
Sometimes the CrashLoopBackOff status activates when Kubernetes does not find runtime dependencies. For example, var/run/secrets/kubernetes.io/serviceaccount files missing. This could happen because some of the containers inside a pod are not operating on the default access token when trying to interact with APIs.
The above scenario could happen if at some point you manually created pods with unique API tokens to access services across a cluster. The service account file missing would be the declaration of tokens that will pass authentication.
To fix this, you can let every other new --mount creation comply with the default access level across your entire pod space. Where new pods are started when a custom token is in use, make sure they comply to avoid perpetual startup failures.
Changes caused by recent updates
If you’re constantly updating your Kubernetes clusters with new variables, sparking resource requirements, chances are they’ll encounter a CrashLoopBackOff.
Say you had a shared master set up, but later ran an update that restarted all pod services. The mere fact that a master has to be elected from among the available options results in several such restart loops.
To fix this trigger, consider changing your update procedure from one that’s brutal (direct and all-encompassing) to one that rolls in changes one pod at a time. This makes your life easier when troubleshooting for the exact source of the failure that sparks a restart loop.
Sometimes you’ll experience the CrashLoopBackOff status as a “settling” phase to the changes you’ve performed…only for the error to resolve itself when each node eventually gets the resources and priority perfect for a stable environment.
Troubleshooting CrashLoopBackOff messages
The process of resolving CrashLoopBackOff states is not as easy as simply pointing at the source, despite what you might be thinking after the possible reasons we just went through. The actual cause-crash matrix is broad.
To start with, the actual applications that benefited the most from Kubernetes scaling could be the cause for the CrashLoopBackOff message as a result of repeated crashing.
Here is the activity process common to the discovery-to-fix a CrashLoopBackOff message.
- The discovery process: This includes learning that one or more pods are in the restart loop and witnessing the apps contained therein either offline or just performing below optimal levels.
- Information gathering: Immediately after the first step, most engineers will run a
kubectl get podscommand to learn a little more about the source of the failure. Common output from this is a list of all pods along with their current state - Drill down on specific pod(s): Once you know which pods are in the CrashLoopBackOff state, your next task is targeting each of them to get more details about their setup. For this, you can run the
kubectl describe pod [variable]command with the name of your target pod as the command variable.
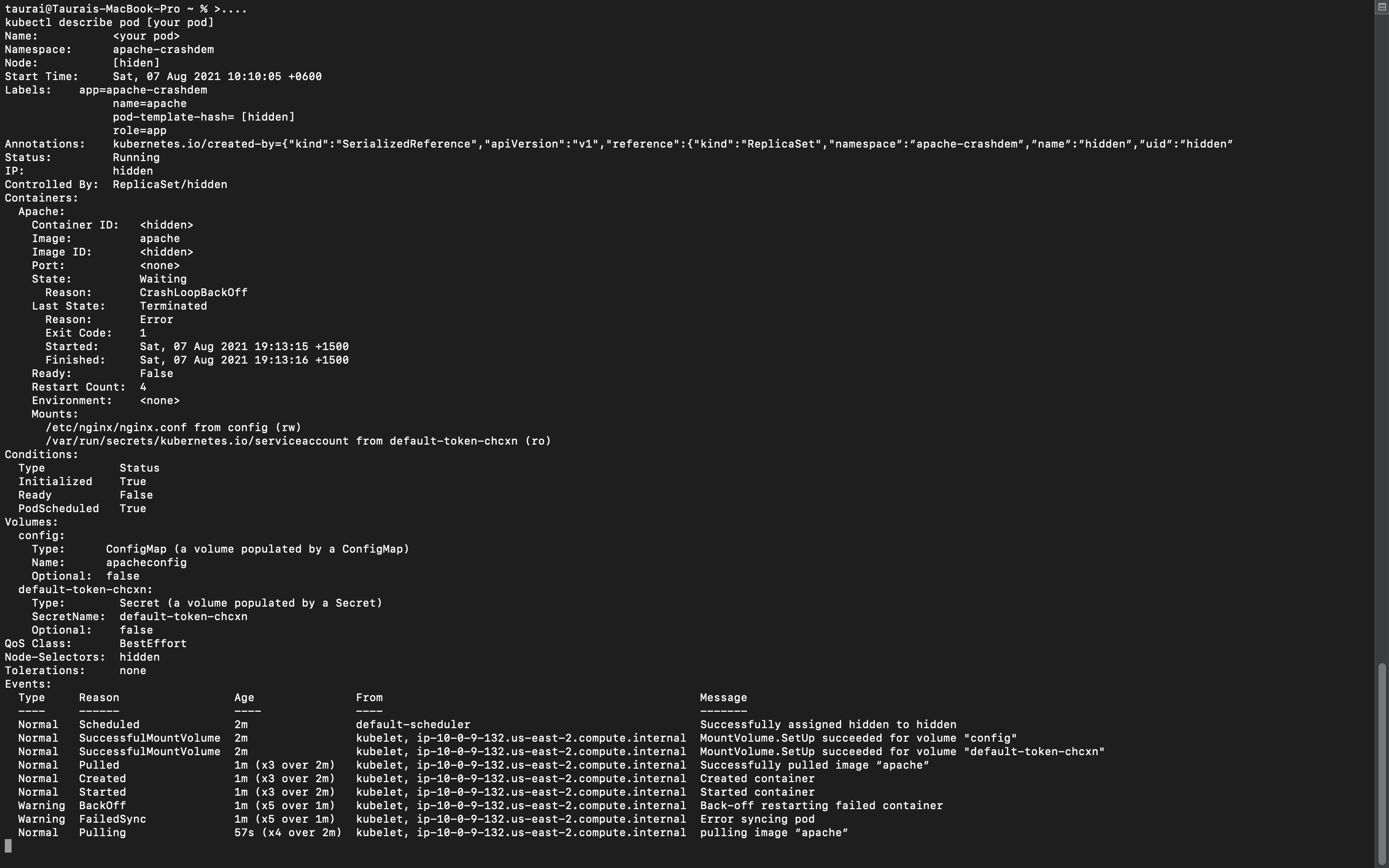
Once you’ve reached this point, several keywords should stick out. Focusing on these should make light work of decoding the list of variables around your pod.
Start time
The timestamp recorded against the start time detail tells you when the node spun into action (or tried to.) Noting this value can be helpful when you’re associating other pod-specific events to the CrashLoopBackOff’s first occurrence.
Mounts:
The mount flag usually lists any other manually added constraints to the pod. This could include (but is not limited to) any secrets and service account token rules and variables. If the default was overridden, this part will be the first clue as to which token is now in use, along the path in which it was declared.
default-token-chcxn:
Farther down the detailed pod variables list is the specification of tokens in use for authentication. If you find that a strict policy is in place, loosening the secret optional status to true and waiting for the next restart could solve the CrashLoopBackOff completely.
Events:
The events section of the printed kubectl describe pod [variable] output will shed immediate light on a pod’s lifecycle. Typically this leads you to the exact event that transpired before the first crash loop.
Using CrashLoopBackOff to your advantage
You can intentionally leave your pod restart policy to always so that they don’t terminate conclusively. This way, you get valuable troubleshooting information when they fail. As we’ve established from one of the common causes of pod failure, some often resolve themselves once changes introduced have propagated.
With CI/CD workflows only capable of filtering out in-app errors (with plugins,) CrashLoopBackOff acts more like an infrastructure check for app versions.
Conclusion
By now, it should be clear why Kubernetes pods reach a state of CrashLoopBackOff. While it’s technically an error status, it’s more of an opportunity to investigate why containers in a pod are failing to attain the Running state. Running the kubectl get pods, then the kubectl describe pod commands against your pods isolates the source of your CrashLoopBackOff status. When the output for these commands prints out, you’ll know when the error starts, what new changes were made to the infrastructure, and if there’s a new API authentication policy. All of that information should point you in the correct direction to resolving the stalemate.
However, even with the above processes being followed, you could still find yourself on a wild goose chase—especially if the event that caused the fail-start loop is not as close to the pod as the kubectl commands are capable of revealing. Because of this very probable case, it’s best to introduce more troubleshooting tools into the fray.
Third-party log and metrics monitoring tools that provide an all-around view of your infrastructure yield more control over quickly resolving CrashLoopBackOff errors. If you're looking for a streamlined way to monitor errors and ensure they are fixed promptly, consider using Airplane. Airplane is the developer platform for building internal tools. With Airplane, you can easily build an engineering workflow or internal dashboard to monitor your Kubernetes pods in real time.
To try it out and build your first monitoring internal tool, sign up for a free account or book a demo.


