


In Linux architecture, memory is separated into kernel space and user space. The kernel space is used to run the core kernel code and the device drivers. Processes running in kernel space have unrestricted access to all hardware, including CPU, memory, and disks. All other processes run in the user space, which relies on the kernel to access the hardware. Processes running in the user space use system calls to communicate with the kernel for privileged operations like disk or network I/O.
This separation creates a secure distinction between various processes, but in some cases the syscall interface is not sufficient and developers need more flexibility to run custom code directly in the kernel without changing the kernel’s source code. For this purpose, Linux provides Linux Kernel Modules, which can be loaded directly in the kernel on demand during runtime.
The kernel modules, however, create security risks since they can run arbitrary code directly in the kernel space. A buggy code in a kernel module can easily crash the kernel. This is why Linux provides a way to run secure, verified sandboxed code in the kernel space through eBPF.
What is eBPF?
BPF, or the Berkeley Packet Filter, was developed from a need to filter network packets in order to minimize unnecessary packet copies from the kernel space to the user space. User space applications like tcpdump are only interested in a small subset of network packets (for example, TCP/IP packets). If the filtering logic is in the user space application, unnecessary packets are copied from the kernel space to the user space. Placing the filtering logic in the kernel prevents those extra copies.
BPF provided a register-based virtual machine with its own instruction set where programs could be safely loaded into the kernel and executed in a secure, sandboxed environment. Since version 3.18, the Linux kernel provides extended BPF, or eBPF, which uses 64-bit registers and increases the number of registers from two to ten. eBPF offers an improved instruction set, which significantly boosts performance.
How eBPF works
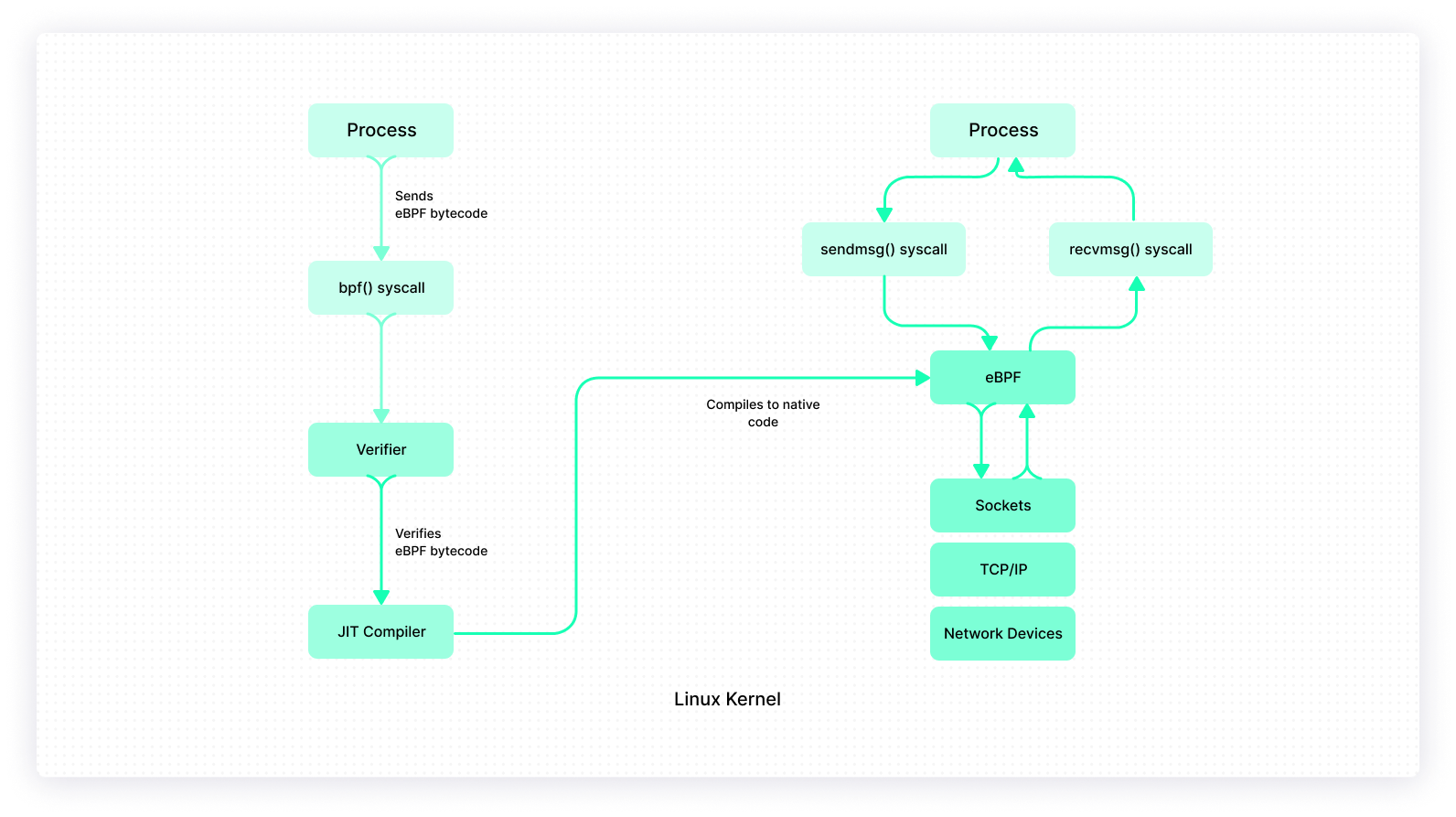
eBPF programs are event-driven, which means they can be hooked to certain events and will be run by the kernel when that particular event occurs. The program can store information in maps, print to ring buffers, or call a subset of kernel functions defined by a special API. The map and ring buffer structures are managed by the kernel, and the same map can be accessed by multiple eBPF programs in order to share data.
eBPF programs follow these steps:
- The bytecode of the eBPF program is sent to the kernel along with a program type that determines where the program needs to be attached, which in-kernel helper functions the verifier will allow to be called, whether network packet data can be accessed directly, and what type of object will pass as the first argument to the program.
- The kernel runs a verifier on the bytecode. The verifier runs several security checks on the bytecode, which make sure that the program terminates and does not contain any loop that could potentially lock up the kernel. It also simulates the execution of the eBPF program and checks the state of the virtual machine at every step to ensure the register and stack states are valid. Finally, it uses the program type to restrict the allowed kernel function calls from the program.
- The bytecode is JIT-compiled into native code and attached to the specified location.
- When the specified event occurs, the program is executed and writes data to the ring buffer or the map.
- The map or ring buffer can be read by the user space to get the program result.
Advantages of eBPF
eBPF is most commonly used to trace and profile user space processes, and more recently as a way to enhance monitoring capabilities. It provides some clear advantages over other methods:
- eBPF moves the task of packet filtering from the user space to the kernel space, thus preventing unnecessary packet copies, which results in a significant performance increase. Because the program is JIT-compiled, it operates quickly.
- eBPF programs are sandboxed and verified, which ensures the kernel doesn’t crash or hang up in a loop. This provides greater security over kernel modules.
- Using eBPF doesn’t require you to modify kernel source code or write full-fledged kernel modules. It is easy to write and execute an eBPF program.
When to use eBPF
eBPF offers the greatest benefits in some specific use cases:
- eBPF is superior to other methods of profiling and tracing user space processes. eBPF programs can be attached to any kernel function and access the context and arguments of the function, as well as modify them. eBPF provides advanced statistical data structures that easily and efficiently extract meaningful data.
- eBPF can implement traffic control, so that packets are directly sent to their destination. This is especially useful in Kubernetes and other container environments in which you have multiple networks, because traffic is usually routed to a container stack. Using eBPF, the complex path between the host and the container stack can be bypassed.
- eBPF can implement security policies in container environments such as Docker or Kubernetes. eBPF is used in XDP (eXpress Data Path) to provide a high-performance, programmable network data path.
When not to use eBPF
eBPF offers many advantages, but it does have limitations. Here are a few situations where eBPF should not be used:
- Since eBPF aims to be secure, it prohibits loops and other high-level constructs, which means the programs are simple and restricted. If you want more control over how the programs are executed, writing a kernel module might be a better choice.
- Executing eBPF programs consumes CPU cycles, and using eBPF instead of built-in tools like iptables might result in a high CPU usage. This will increase the costs from your cloud provider.
- eBPF is not suited for a use case in which you need to process every packet, such as in decryption and re-encryption of packets. Per-packet processing will be expensive and relatively slow.
Getting started with eBPF
Writing an eBPF program directly in the bytecode is extremely hard. Fortunately, you can write the program in other languages and compile it to the eBPF bytecode. You’ll also need to write a user space program that attaches this bytecode to the kernel and interacts with it. The most straightforward way to write an eBPF program is to use BCC (BPF Compiler Collection), which provides frontend for eBPF in C++, Python, and Lua. For this example, you will be using the Python frontend.
To follow along, you need to install BCC and create a file called bpf.py.
First, import the required module:
Now using C, write the code for the eBPF program that will be executed in the kernel. You can either write the C program inside Python and store it as a string variable, or write it in a separate file and read that file into the Python program. We will be taking the first approach.
Let’s understand the C program. It defines a simple function named kprobe__sys_clone. The name of the function tells BCC where to attach it. Since the name starts with kprobe__, it defines a kprobe to trace a kernel function. The rest of the function name defines which kernel function to trace, in this case sys_clone. The function takes one argument, ctx. This is actually the type struct pt_regs *, which holds the registers and the BPF context. Since you will not be using this argument here, it is cast to void *. The function can include as many of the probed function arguments as you want, as long as the first argument is ctx.
Inside the function, we are using bpf_trace_printk to print hello world to the kernel’s common trace_pipe. Finally, return 0; is a necessary formality.
Compile the program, verify it, and load it into the kernel. All of this is handled by the BPF class:
Read the kernel’s trace_pipe and print the messages:
This sets up a trace_fields loop, which performs a blocking read on the trace_pipe and returns a fixed set of information about the execution of the traced function. Finally, print the fields you need. The values task and msg are bytes, so call decode to convert them into strings.
To run this program, you will need superuser permission. Run the program with sudo:
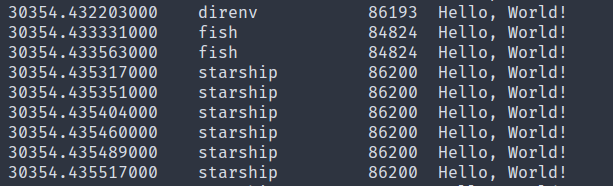
Now open up another shell and run any command like ls or cat that will trigger the clone call. Your eBPF program will be executed and the output will be printed. Here is a sample output:
For more code samples, check the BCC examples directory.
Conclusion
eBPF is an excellent advancement for the Linux kernel. The ability to run code in a secured and sandboxed fashion in the kernel is a valuable tool for observability, network traffic control, and containerization.
If you want to learn more about eBPF and access community resources, conferences, and blogs, visit ebpf.io. The BCC docs are great to get started quickly with code samples. However, you may also want to consider using libbpf as an alternative to BCC. Finally, the Awesome eBPF repo aggregates multiple resources for further research.
If you're looking for an internal tooling platform that makes it easy to build powerful workflows and UIs, then try out Airplane. Airplane is the developer platform for building custom internal tools. With Airplane, you can build single or multi-step operations easily. You can also build Views, React-based custom UIs using pre-built components and templates.
Sign up for a free account or book a demo to try it out and build custom UIs easily.


